Master projects
Here you can find all our available master projects.
Open Projects (129)
-
Diffusion models for high-resolution probabilistic weather modelling
The domain of weather forecasting is currently undergoing a significant transformation driven by advances in machine learning, where Data-Driven Models (DDMs) have demonstrated equal or superior performance compared to traditional Numerical Weather Prediction (NWP) models in predicting various variables, while operating at a fraction …
 Vlado Menkovski
More infoSBSophie Buurman
Vlado Menkovski
More infoSBSophie Buurman -
Simulating the Cosmic Web: Flow Matching Generative Models for Large-Scale Cosmological Structures
The large-scale structure of the universe is governed by the gravitational evolution of dark matter, forming an intricate cosmic web of filaments, expansive voids, and massive galaxy clusters. High-resolution N-body simulations, such as the Quijote suite, are the standard method for producing these theoretical …
More info
Vlado Menkovski
-
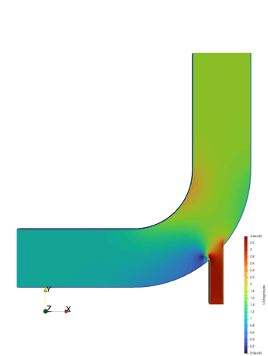
Data-driven modeling of preconditioners
Ignition Computing is developing a toolbox to speed up the solving of sequences of systems of linear equations. Solving such a system is at the core of many computationally expensive multi-physics simulations, such as those arising in Computational Fluid Dynamics (CFD).A central challenge in …
Vlado Menkovski
More infoIWIris van der Werf -
Neural surrogate modeling of biomolecular condensate morphology
Mapping the phase behavior of biomolecular condensates across a multi-dimensional parameter space is a fundamental challenge in soft matter science, relevant to materials design and drug delivery. Automated platforms can navigate this space using active machine learning, but current approaches rely on a binary …
Vlado Menkovski
More infoNENadia Erkamp -

Deep Removal of Active Galactic Nuclei
Almost all massive galaxies harbor a central supermassive black hole (SMBH). As these SMBHs grow by accreting surrounding gas and dust, they liberate tremendous amounts of energy, becoming visible as Active Galactic Nuclei (AGN). While the AGN phase is incredibly important for understanding galaxy …
Vlado Menkovski
More infoLWLingyu Wang -
Empirical Understanding of simple MAP queries in discrete multivariate domains
This project will (empirically) investigate and extend the findings in Almost No News on the Complexity of MAP in Bayesian Networks (https://proceedings.mlr.press/v138/campos20a.html) It requires some coding and desire to run sound and thorough (empirical) analyses.
More info Cassio de Campos
Cassio de Campos
-
Uncertainty Quantification via Test Time Augmentation
Test-Time Augmentation (TTA) refers to applying data augmentations not only during training, but also during inference. For a single input, such as an image, the model is evaluated on multiple augmented versions of that input, for example rotated or cropped variants. The final prediction …
 Sibylle Hess
More info
Sibylle Hess
More info Fabian Denoodt
Fabian Denoodt
-

Large Models for Robotic Manipulation in Healthcare: Dual- Arm Large model performance in Real-World Deployments
ObjectiveThe goal of this project is to train, deploy and evaluate embodied multimodal (large) models to perform dual-arm manipulation tasks relevant to healthcare assistance. The student will work towards a demonstration task. In the work leading up to the demonstration, the student will train …
 Bram Grooten
More info
Bram Grooten
More info Joaquin Vanschoren
Joaquin Vanschoren
-
Complexity of MAP in simple mixture models
This is a theoretical project that will connectMinimizing Low-Rank Models of High-Order Tensors: Hardness, Span, Tight Relaxation, and Applications (https://ieeexplore.ieee.org/document/10342630)andAlmost No News on the Complexity of MAP in Bayesian Networks (https://proceedings.mlr.press/v138/campos20a.html) generating new theoretical results and fixing imprecisions on existing one. It requires a student …
More info
Cassio de Campos
-
Credal models for reasoning shortcut awareness
Reasoning shortcuts can be harmful for AI systems which want to achieve a high level of "understanding" and reasoning capabilities. The XOR MNIST example illustrates well the current situation (see https://arxiv.org/abs/2507.11357 and https://proceedings.mlr.press/v244/marconato24a.html). This project will attempt to use credal models to represent those …
More info
Cassio de Campos
-
Beyond monotone circuits
This project will study the representation and learning capabilities of circuits that are not monotone. The basis for the work starts with https://arxiv.org/abs/2310.00724 and https://arxiv.org/abs/2408.00876We will empirically study different types of circuits and attempt to unveil what makes them work (or not).
More info
Cassio de Campos
-
Structure learning for multi-dimensional classifiers
This project intends to extend the work in:https://proceedings.mlr.press/v216/nguyen23b/nguyen23b.pdfby adapting ideas for credal structure learning (via optimistic and pessimistic approaches). The theory is being developed by colleagues at UT Compiegne (led by prof VL Nguyen), with whom we will interact to reach the project goals.
More info
Cassio de Campos
-
Structure learning of circuits
Structure learning of (probabilistic) circuits is an open problem. This project will attempt to create new ideas and algorithms. Some references:Tractable Uncertainty for Structure Learning: https://arxiv.org/abs/2204.14170Strudel: Learning Structured-Decomposable Probabilistic Circuits: https://arxiv.org/abs/2007.09331Bayesian Structure Scores for Probabilistic Circuits: https://arxiv.org/abs/2302.12130
More info
Cassio de Campos
-
Synthetic incomplete data generation
Data generation is an important task, but typically the missing data mechanism is not fully modeled and exploited in the process. This project intends to study such a problem and to create tools for data generation with missing values. Besides data generation from random …
More info
Cassio de Campos
-
High-Throughput Computational and Data Pipeline for iSCAT Microscopy
Interferometric scattering (iSCAT) microscopy is a technique to detect small particles (like individual proteins or live viruses) by capturing the interference between scattered light and a reference reflection. Currently, a major bottleneck is computational: there is a need for an end-to-end data streaming architecture …
 Robert Brijder
More infoAKAnna Kashkanova
Robert Brijder
More infoAKAnna Kashkanova -
AI‑Driven Legal Search with Knowledge Graphs for Dutch Jurisprudence
[Please note that this project is primarily aimed at Dutch-speaking students, as it requires working with large amounts of Dutch texts.]AI-powered search has rapidly become the new standard for search engines. However, popular techniques (e.g. AI agents or retrieval-augmented generation), face fundamental limitations when …
More info Hilde Weerts
Hilde Weerts
-
Adaptive Inference Time in Neural Networks with Early-exit Neural Networks & Uncertainty Quantification
Increasing a neural network's architecture size can significantly improve performance, but it also makes inference slow and resource-intensive. Early-exit neural networks (EENNs) address this by adding extra classifiers at intermediate layers, so that easy inputs can exit early and save computation. The key question …
Sibylle Hess
More info
Fabian Denoodt
-
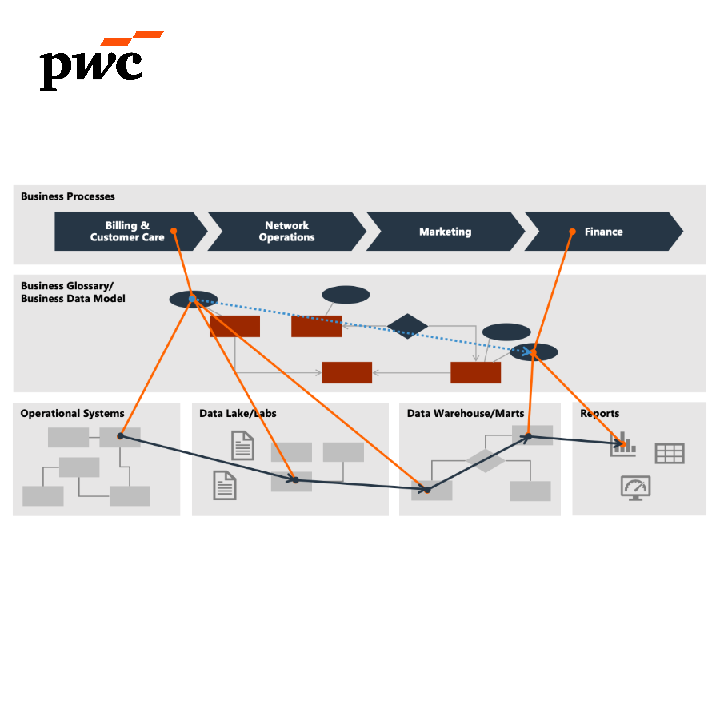
(External: PwC) "Where does this number come from?": Enterprise Data Lineage using LLMs and Knowledge Graphs
In Financial and ESG reporting, we see that it takes a lot of time to create insights into data lineage of the reports that companies publish on their Financial, Environmental, Social and Governmental related KPIs. Quality, transparency and integrity would be supported if we …
More info Bart Engelen
Bart Engelen
-
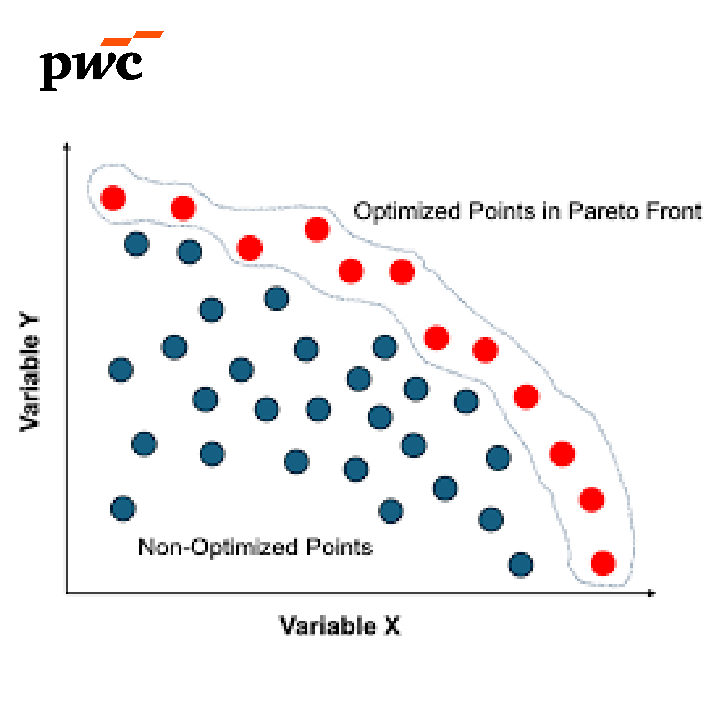
(External: PwC) Optimization and Pareto fronts in the Responsible Business Simulator
Introduction In the current business landscape, companies are balancing profitability and social responsibility. The Responsible Business Simulator (RBS) is a powerful tool designed by PwC to help businesses make responsible strategic choices by simulating the impact of various decisions on diverse outputs. This master's …
More info
Bart Engelen
-

(External: PwC) Write your thesis at PwC Advisory Data Analytics
Do you want to write your master's thesis about a Data & AI related topic on real-world client cases? We offer you the opportunity to write your thesis within PwC's Data Analytics Advisory team. This is a multidisciplinary team that uses its analytical skills …
More info
Bart Engelen
-
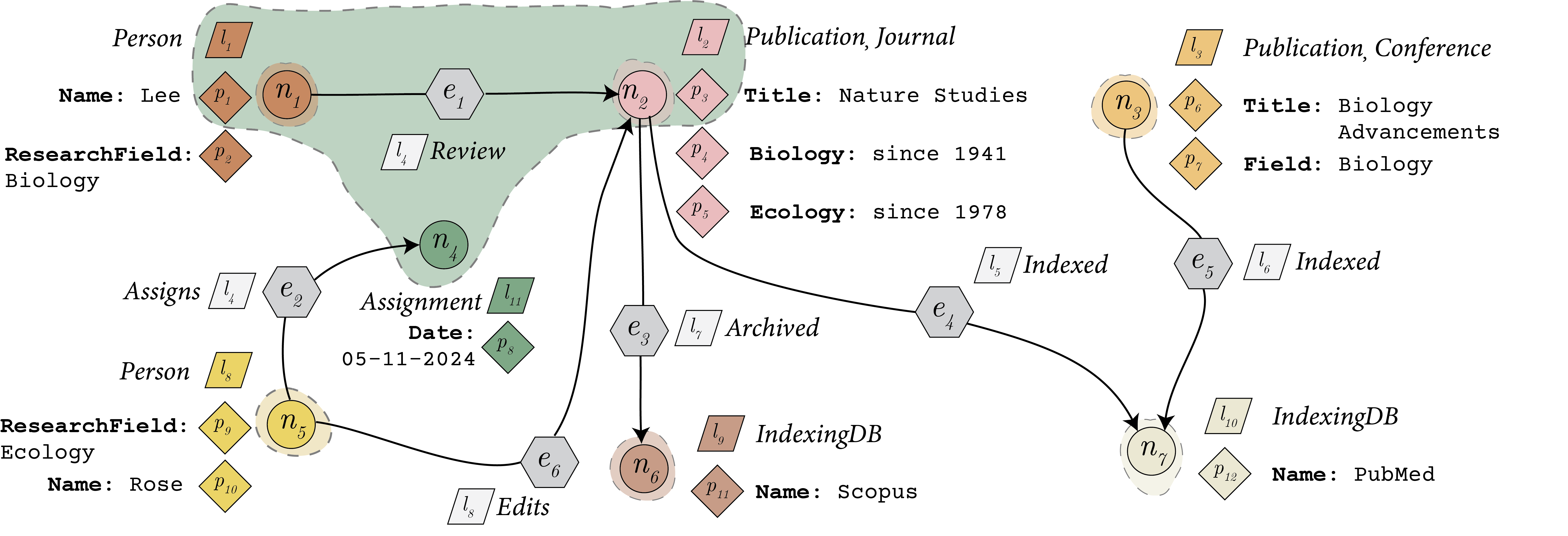
From Querying to Updating: Towards DML Support for a Metadata-Aware and Annotatable Graph Database
Property graph databases such as Neo4j are widely used these days for various applications like knowledge graphs backed LLM pipelines and modeling interconnected data, but traditional systems treat metadata (e.g., labels and property keys) separately from data and offer limited support for annotating subgraphs. …
 Nick Yakovets
More info
Nick Yakovets
More info Sepehr Sadoughi
Sepehr Sadoughi
-
Towards Meaningful Metrics for Monosemanticity and Disentanglement
Recent work in representation learning—especially in interpretability research—frequently refers to monosemanticity: the idea that individual units (neurons, features, or directions in representation space) correspond to a single, well-defined concept. Closely related is the notion of disentanglement, where different latent dimensions are expected to capture …
Sibylle Hess
More info Surja Chaudhuri
Surja Chaudhuri
-
Semantic Hashing of the Epstein Files
Large investigative document releases often contain tens of thousands of heterogeneous files: transcripts, motions, scanned exhibits, emails, duplicates, partially redacted documents, and large amounts of procedural boilerplate. In practice, sheer volume can become a filtering mechanism. When everything is available, nothing is easily accessible. …
More info
Sibylle Hess
-
Synopses for continual learning
In this project you will consider the use of synopses (course 2AMD15) for continual learning. You will (a) explore how existing synopses can be used to support continual learning tasks, e.g., to mitigate forgetting (b) develop novel sketches, if needed, (c) prove their properties …
 Odysseas Papapetrou
More info
Odysseas Papapetrou
More info Mykola Pechenizkiy
Mykola Pechenizkiy
-
Offline Model-based Reinforcement Learning
Offline Reinforcement Learning (RL) addresses settings where online interaction is impractical, costly, or unsafe, enabling applications from healthcare to robotics. Learning from offline data is challenging due to distributional shift, which causes extrapolation errors that cannot be corrected without further exploration. Model-free RL methods …
More info Maryam Tavakol
Maryam Tavakol
-
Making the Invisible Visible: Identifying and Linking Internal Knowledge Sources in an Industrial KG
BackgroundMarel, a global leader in the food processing industry, specializes in designing and manufacturing advanced machinery for processing poultry, meat, and fish. Effective knowledge sharing among engineers at Marel is important for sustaining business operations. DescriptionThis project will explore how internally referenced knowledge sources—such as …
 George Fletcher
More info
Sepehr Sadoughi
George Fletcher
More info
Sepehr Sadoughi
-
Knowledge Archeology from Homebrew Data Sources: Integrating Informal Information Sources Into the KG
BackgroundMarel, a global leader in the food processing industry, specializes in designing and manufacturing advanced machinery for processing poultry, meat, and fish. Effective knowledge sharing among engineers at Marel is important for sustaining business operations. Description“Homebrew” systems are fragmented knowledge artifacts such as spreadsheets, ad-hoc …
George Fletcher
More info
Sepehr Sadoughi
-
Is SQL sufficient to support visual analytics
Databases often act as the backend for visualization -- to safely store the data, and to aggregate/serve it to the visualization layer efficiently, such that it is shown to the user in a way that helps decision making. This connection between the two layers …
More info
Odysseas Papapetrou
-
Applications of minwise sampling
Minwise sampling (or MinHash) is a collection of methods that estimate similarity between sets. Most methods assume static data. A new method, designed last year in our group, also works with non-static (i.e., streaming) data, and it can support deletion. This thesis will focus …
Odysseas Papapetrou
More infoWPWieger R. Punter (PhD student) -
Building an AI avatar
This project is for Dutch-speaking students only, since it requires working with large amounts of Dutch data and requires Dutch cultural knowledge.This project aims to create an AI avatar that is trained to act like a well-known Dutch entertainer. It is to be trained …
More info
Joaquin Vanschoren
-
Learning to Optimize at Scale with Attention Mechanisms
Continual learning refers to the ability of a system to continually acquire new knowledge over time while retaining previously learned experience [1]. Conventional neural networks typically update all model parameters (weights) when adapting to new tasks, which often leads to catastrophic forgetting [2]. Instead, …
Joaquin Vanschoren
More info Anna Vettoruzzo
Anna Vettoruzzo
-
From Tables to Pixels: Adapting Tabular Foundation Models for Vision Tasks
Foundation models have recently demonstrated remarkable capabilities across a wide range of domains by learning from large-scale data and generalizing to novel, unseen tasks without the need for fine-tuning. This generalization ability is primarily enabled by their capacity for in-context learning, which is the …
Joaquin Vanschoren
More info
Anna Vettoruzzo
-
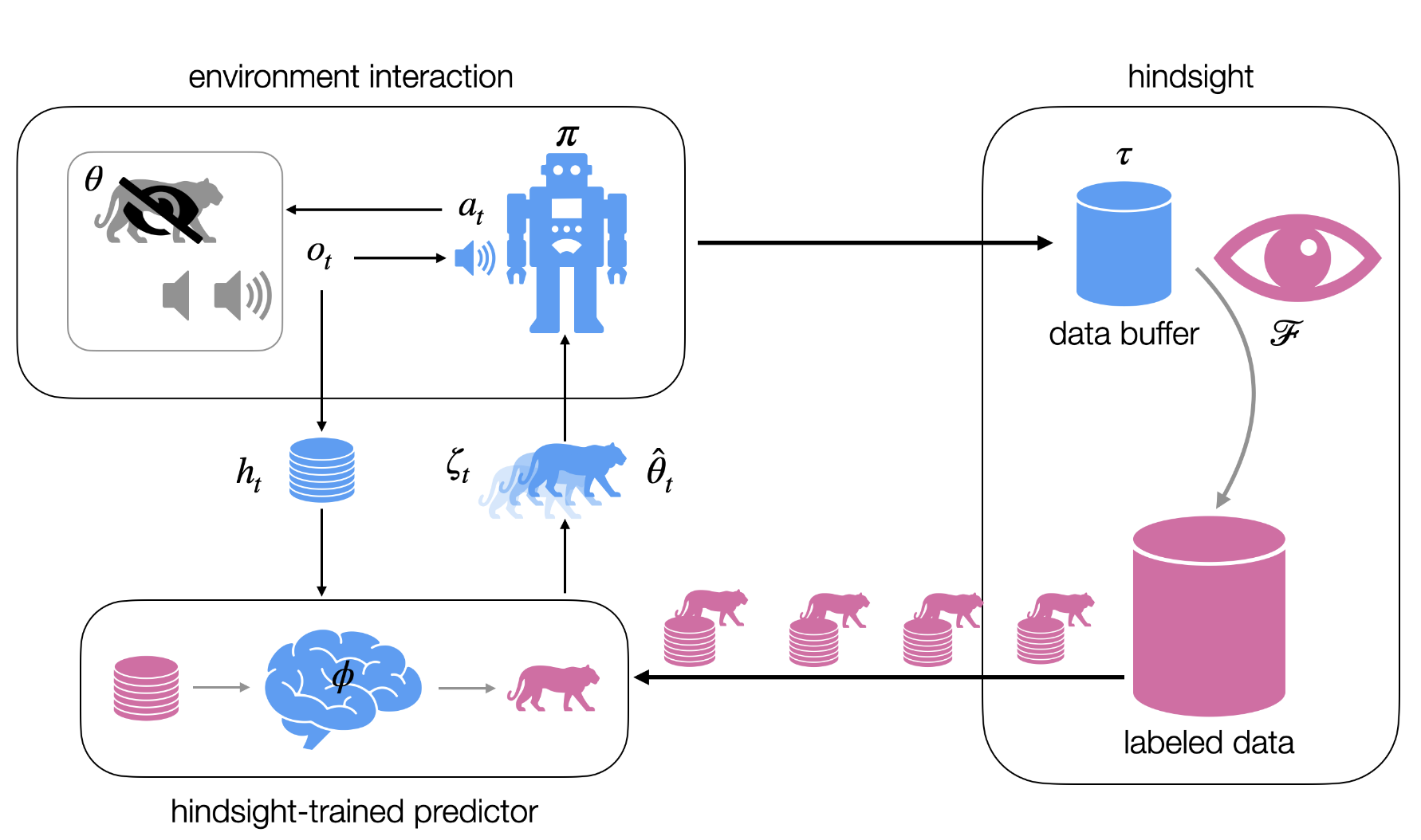
Using Privilled Information in Sequential Decision Making with Partial Observations
Reinforcement Learning (RL) (Sutton and Barto, 2018) addresses problems that can be modeled as a Markov decision process (MDP) (Puterman, 1994), where the transition function is unknown. In situations where an arbitrary policy is already in execution and the experiences with the environment were …
 Thiago Simão
More info
Maryam Tavakol
Thiago Simão
More info
Maryam Tavakol
-
Your own MSc project in databases at a company
If you have found a MSc project at a company with a strong database angle, then I am open to supervising. Note: a MSc project isn't an internship, and so the project must have a clear, relevant, and challenging research problem. Also, a strong …
More info
Robert Brijder
-

Scaling granular material simulations with deep geometric generative models (TAKEN)
Granular materials are one of the world’s most widely used and manipulated materials, only behind water. The modelling of these materials is relevant to various sectors, including energy production, agriculture, cosmetics, construction, and the pharmaceutical industry. Granular materials are collections of discrete particles, which …
More info
Vlado Menkovski
-
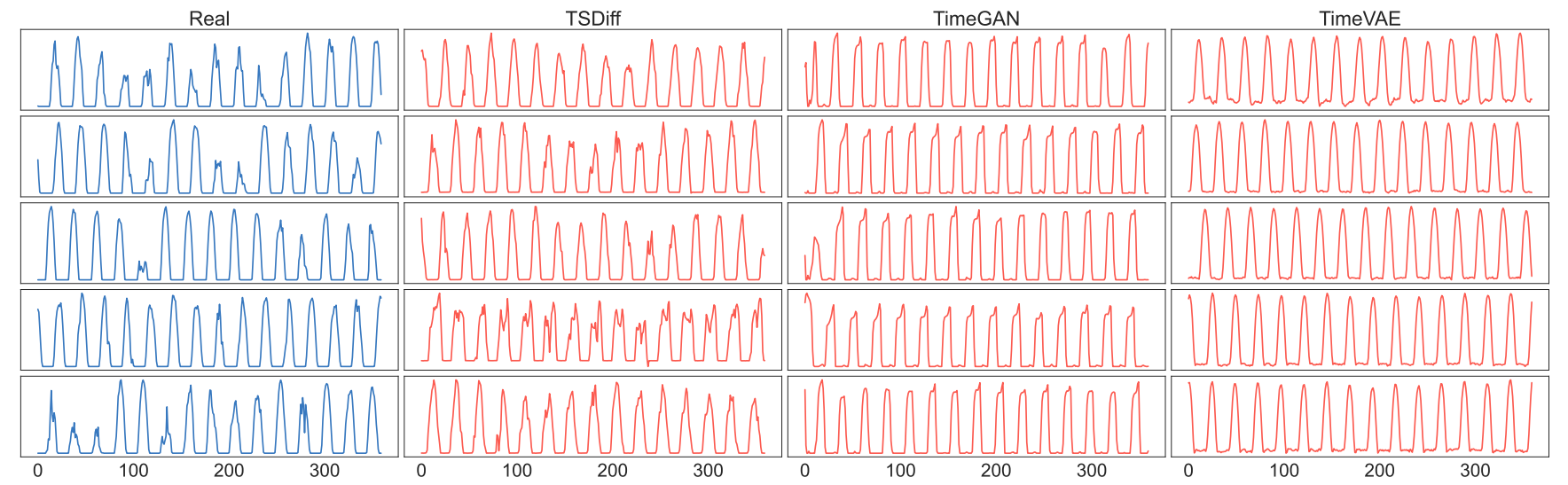
High-Quality Long Time Series Generation with Deep Generative Models: Exploring Flow Matching and Exogenous Data Integration (TAKEN)
Time series data—prevalent in finance, healthcare, and climate science—requires advanced generative models for tasks like data augmentation, anomaly detection, scenario planning, and synthetic data generation. Deep Generative Models (DGMs), such as Diffusion Models (DMs) and Flow Matching (FM) models, have emerged as powerful tools …
Vlado Menkovski
More info Mahdi Mehmanchi
Mahdi Mehmanchi
-
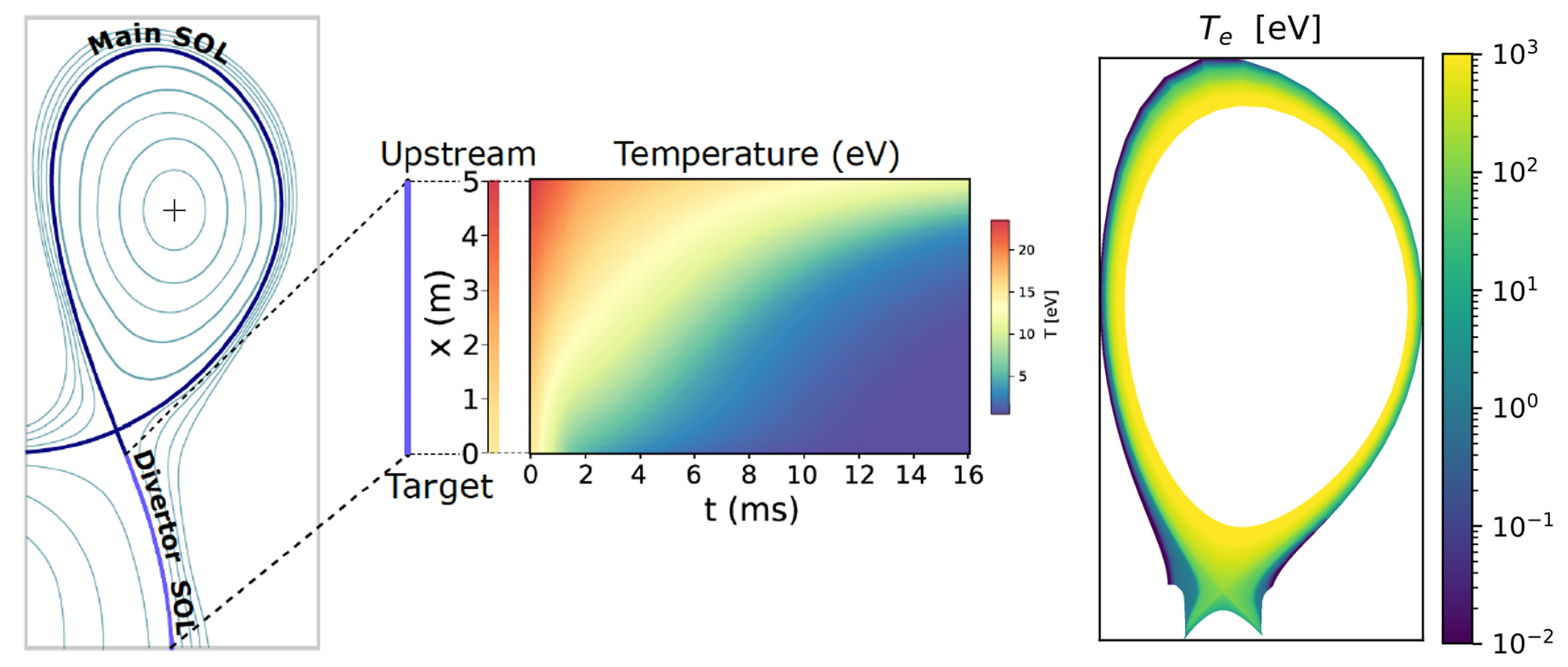
Nuclear fusion: Coupling 1D and 2D simulation of Tokamk Plasmas with deep generative models (TAKEN)
[For this project there is a possibility for a 6 months internship at DIFFER (Dutch Institute for Fundamental Energy Research) located at the TU/e campus in Eindhoven. The internship is planned after the preparation phase of the graduation project conditioned on the results achieved …
More info
Vlado Menkovski
-
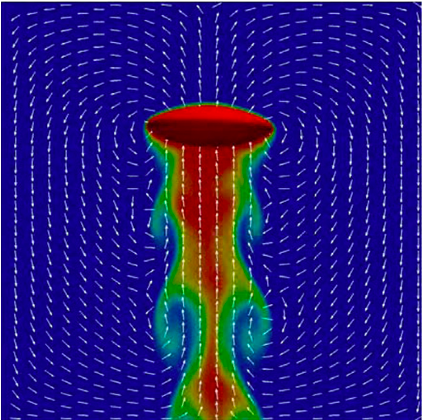
Simulation of bubbly flows with deep generative modeling (FINISHED)
The topic of the project is simulation of bubbles with deep generative models. Bubbles are a fascinating phenomenon in multiphase flow, and they play an important role in chemical, industrial processes. Bubbles can be simulated well with a first-principle physics simulator based on the …
More info
Vlado Menkovski
-
Extending Omnisketch
In [1] we proposed OmniSketch, the first sketch that supports OLAP-like analytics. In this thesis you will consider either of the two options: (a) distributing OmniSketch such that it works efficiently over large clusters, (b) making it able to handle sliding windows queries, by using …
Odysseas Papapetrou
More info Wieger Punter
Wieger Punter
-
Spatial sketches -- topic 1
The recent work "Synopses for summarizing spatial data streams" describes a framework that allows any existing synopsis to summarize spatial data. This thesis focuses on further extending this work by replacing the simple regular grid structure that is used now with other, more space …
Odysseas Papapetrou
More info
Wieger Punter
-
Spatial sketches -- topic 2
The recent work "Synopses for summarizing spatial data streams" describes a framework that allows any existing synopsis to summarize spatial data. This thesis focuses on further extending this work by rethinking the allocation of space in the spatial sketch. For example, areas in the …
Odysseas Papapetrou
More info
Wieger Punter
-
Creating Fairness-Aware Datasets for Sequential Decision-Making
As AI systems become more integrated into decision-making across domains such as finance, healthcare, and criminal justice, ensuring fairness has become a key concern. Fairness-aware machine learning (ML) aims to mitigate biases that could lead to discriminatory outcomes, but traditional research often focuses on …
More info
Maryam Tavakol
-
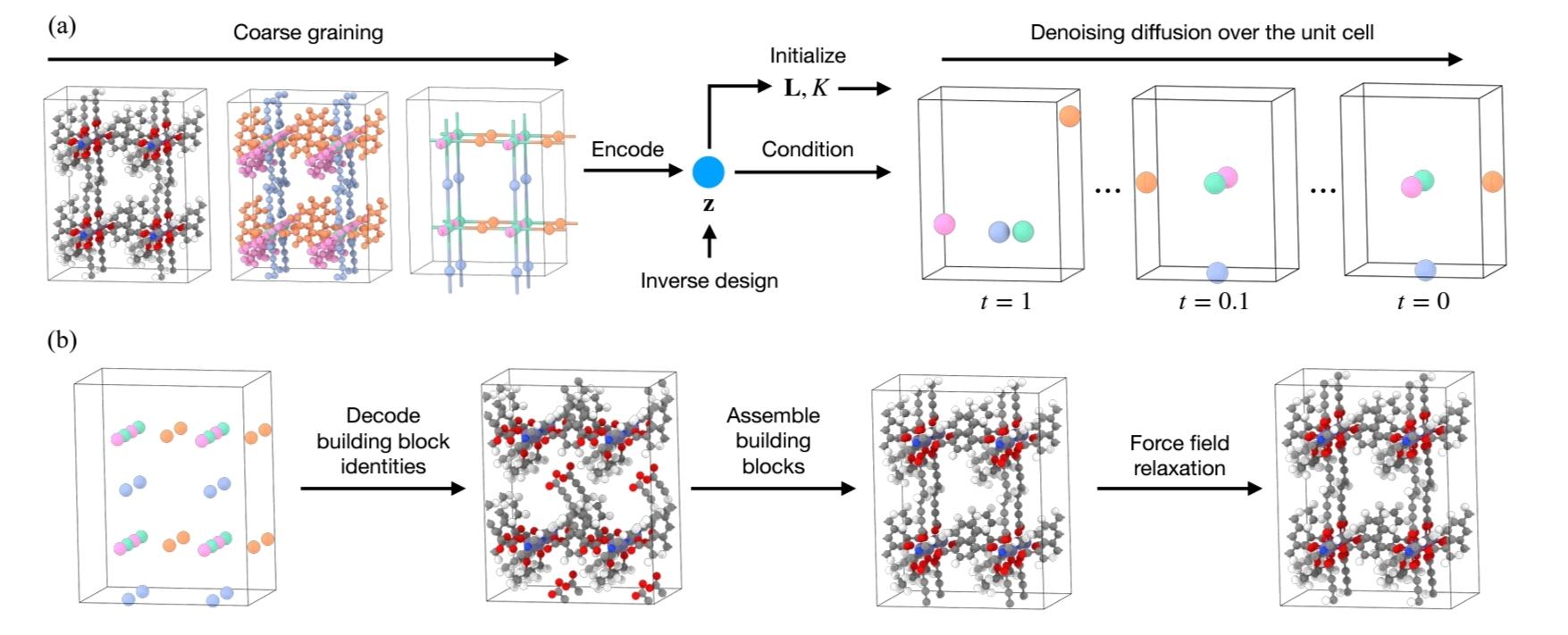
Atom-Level Generative Modeling of Metal-Organic Frameworks with Graph Transformers (FINISHED)
Metal-organic frameworks (MOFs) are crystalline, porous materials with modular architectures and vast structural diversity, making them ideal candidates for data-driven materials discovery. In recent years, generative machine learning models have been developed to explore the MOF design space by assembling frameworks from pre-defined building …
Vlado Menkovski
More info Marko Petkovic
Marko Petkovic
-
Synopses meet machine learning
Training ML models over big data is a time-consuming and energy-hungry process. Furthermore it requires full access over the data, which is challenging in many use cases, due to the size of the data. The problem is particularly challenging when the data is read …
Odysseas Papapetrou
More info
Mykola Pechenizkiy
-
Time-series search: to index or not to index
Time series data is widely generated and used across various fields, including healthcare, finance, and surveillance. For example, in the stock market, the changes in stock prices throughout the day form a time series. In such contexts, it is often important to perform searches—either …
More info
Odysseas Papapetrou
-

[Internship at TeleOperation]Enhancing Real-World Imitation Learning with Reinforcement Learning
This TU/e master project is setup in collaboration with a robotics start-up in Eindhoven. Applications are now open and will remain open until a suitable candidate is found (details below).Company OverviewTeleOperation Services is an innovative company based in Woensel-Noord, Eindhoven. Our cutting-edge AI-driven system …
Thiago Simão
More info
Bram Grooten
-

Race Car Tuning as Configurable Reinforcement Learning
Deep reinforcement learning has been successfully used for driving a car in the Gran Turismo video game, outperforming experts (Wurman et al., 2022). However, an open question remains: how to tune the car used during the races?This problem can be modeled as a configurable …
More info
Thiago Simão
-
Long-term Fairness with Offline Reinforcement Learning
One of the main concerns in the recent AI research is that most data-driven approaches preserve the bias or unfairness available in the collected (offline) data in the resulting models, which could lead to harmful social and ethical effects in the society. Fairness-aware machine learning has …
More info
Maryam Tavakol
-
Reinforcement Learning for Efficient Causal Discovery
Understanding causal relationships within data is essential across fields such as healthcare, economics, and social sciences, where knowing "what causes what" guides decision-making and policy. Causal discovery, the process of identifying these relationships and structuring them in causal graphs, remains challenging, especially in complex, …
 Devendra Dhami
More info
Maryam Tavakol
Devendra Dhami
More info
Maryam Tavakol
-
Causal Discovery for Offline Model-Based Reinforcement Learning
Reinforcement Learning (RL) has proven effective in a variety of complex decision-making tasks. However, traditional RL requires extensive online interactions, making it costly and, in some domains, impractical due to constraints on safety, time, or resource availability. Offline RL, which relies solely on pre-collected …
Maryam Tavakol
More info
Devendra Dhami
-
Part replacement identification using Knowledge Graphs
(This project is also available as an internship)Company: Marel Location: Boxmeer BackgroundIt is important for industrial equipment developers to provide accurate part replacements to their customers. Parts can wear over time or break and having suitable replacements is a dynamic process based on availability, …
Mykola Pechenizkiy
More info Zeno van Cauter
Zeno van Cauter
-
Maintenance and Real-Time Updating of Deployed Knowledge Graphs
(This project is also available as an internship)Company: Marel Location: BoxmeerBackgroundKnowledge Graphs have emerged as a powerful tool for representing vast amounts of interconnected data. By structuring data in a graph format, enterprises can uncover relationships and insights that are often hidden in traditional …
Nick Yakovets
More info
Sepehr Sadoughi
-
Context-aware knowledge retrieval from KGs for technical support thinking assistant
Background: Knowledge Graphs (KGs) are structured representations of knowledge, that organize information in a graph-based format, where entities (nodes) and the relationships between them (edges) represent facts in an interconnected network. This graph-based structure enables encoding complex interrelationships and semantic information, making it an …
Nick Yakovets
More info
Sepehr Sadoughi
-
Implementing the Graph Pattern Matching Language (GPML) Fragment for GQL on AvantGraph
Graph databases have emerged as a powerful contender to traditional relational databases, especially in areas where complex relationships and interconnections are required, such as social networks and knowledge graphs. This has led to the development of various query languages to interact with graph databases, …
Nick Yakovets
More info
Sepehr Sadoughi
-

Alternative latent space models for vessel re-identification
— not available anymore —Coastal surveillance cameras are often used to detect (distinguish from the background) and recognize (as belonging to a class) non-cooperative vessels, i.e. vessels not reporting their position and identity using an AIS [1] transponder through a TDMA network such that …
Mykola Pechenizkiy
More info Stiven Schwanz Dias
Stiven Schwanz Dias
-
Vision-centric image tokenization in the generative transformer era
Generative autoregressive next token prediction has shown impressive success in LLMs. Several works have attempted to extend the success of LLMs to vision-language tasks with VLMs. While a VLM can be designed specifically for image-to-text tasks like visual question answering, many works also attempt …
 Bahram Zonooz
More info
Bahram Zonooz
More info Elahe Arani
Elahe Arani
-
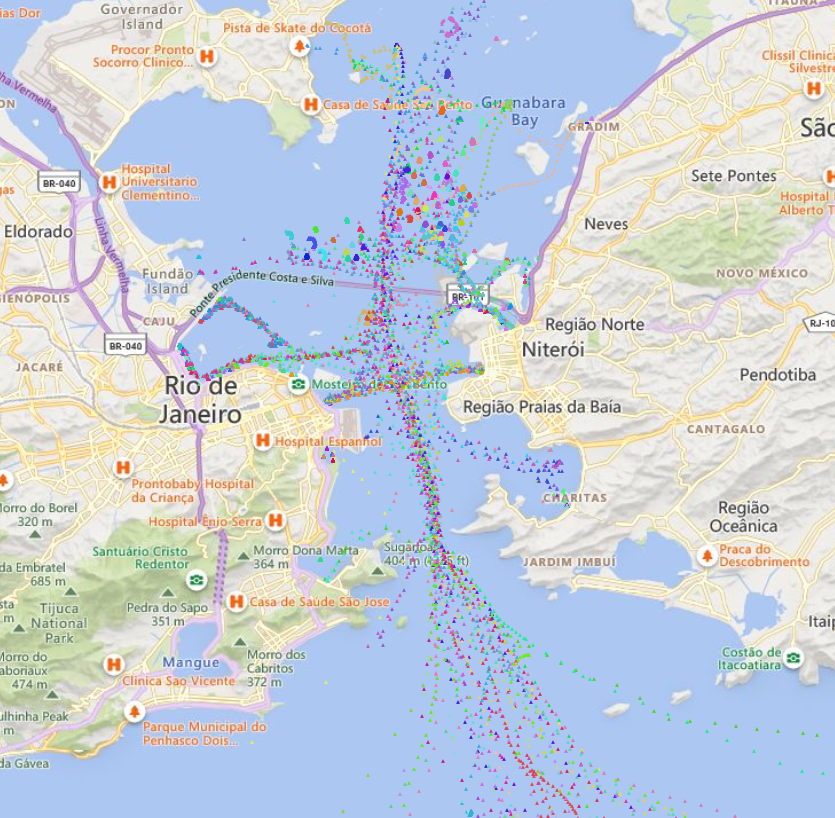
Maritime traffic anomaly detection
— not available anymore —Coastal surveillance systems rely on multiple sensors to perform object assessment [1], i.e., to detect and track the sequence of vessels' states including their position and velocity (where are the vessels at a given timestamp?). In general, surface radars are …
Mykola Pechenizkiy
More info
Stiven Schwanz Dias
-
Leveraging Language Semantics for Enhanced Understanding and Generalization
The field of artificial intelligence has seen unprecedented growth in recent years, particularly with the advent of foundation models and large language models (LLMs). These models have showcased remarkable capabilities across a broad spectrum of applications, including natural language processing and multimodal tasks. Traditionally, …
Bahram Zonooz
More info
Elahe Arani
-
Architectural Analysis of Vision Transformers in Continual Learning
Deep neural networks (DNN) deployed in the real world are frequently exposed to non-stationary data distributions and required to sequentially learn multiple tasks. This requires that DNNs acquire new knowledge while retaining previously obtained knowledge and this is imperative in applications like autonomous driving …
Bahram Zonooz
More info
Elahe Arani
-
True continual learners in the wild: CL beyond artificial constraints / datasets
Continual Learning (CL) is a learning paradigm in which computational systems progressively acquire multiple tasks as new data becomes available over time. An effective CL system must find a balance between being adaptable to integrate new information and maintaining stability to prevent disruption of …
Bahram Zonooz
More info
Elahe Arani
-
Exploring sparsity in lifelong learning
In the dynamic world, deep neural networks (DNNs) must continually adapt to new data and environments. Unlike humans, who can learn continually without forgetting past knowledge, DNNs often suffer from catastrophic forgetting when exposed to new data, causing them to lose previously acquired information. …
Bahram Zonooz
More info
Elahe Arani
-
Image representation learning in autoregressive transformers
With the recent success of LLMs, and the strong potential of multi-modal learning from both text and vision, several works have framed images as sequences to conform with generative sequence-to-sequence encoder-decoder or decoder based transformers [1]. Such formulations present advantages such as unified architectures …
Bahram Zonooz
More info
Elahe Arani
-
Examples of missing not at random (MNAR) data that are difficult for classifiers
It often occurs in datasets that there is missing data. A good introduction can be found here: https://stefvanbuuren.name/fimd/.This missingness might be "completely at random" (MCAR). This occurs when the probability of being missing is the same for all cases. An example of MCAR data …
More info Arthur van Camp
Arthur van Camp
-
Implementation of inference algorithms for the imprecise Plackett–Luce model
The Plackett–Luce model is a popular parametric probabilistic model to define distributions between rankings of objects, modelling for instance observed preferences of users or ranked performances of algorithms. Since such observations may be scarce (users may provide partial preferences, or not all algorithms are …
More info
Arthur van Camp
-
Show me the path: do people only care about paths?
Paths in graphs are natural, arising in domains as diverse as social networks (e.g., which people are in the same community?), communication networks (e.g., how does information spread via SMS messages?), and literary networks (e.g., which scientific papers are the most influential, in terms …
George Fletcher
More infoSBSourav Bhowmick (NTU Singapore) -

AI for 3D Concrete Printing
— not available anymore —Designing 3D printable materials has been, so far, a trial-and-error process dependent on human knowledge and effort; hence time-consuming and wasteful. To predict certain properties of 3DCP, material scientists have used modelling and simulations for decades. While helpful in many …
Mykola Pechenizkiy
More infoSBSandra Lucas and Önder Babur -
Counterfactual explanations
I plan to offer a few assignments on counterfactual explanationsCounterfactual explanations on evolving dataFeasibility, actionability and personalization of counterfactual explanationsCounterfactual explanations for spotting unwanted biased in predictive model behaviourValue alignment for counterfactual explanations (in collaboration with Emily Sullivan)Counterfactual explanations for behaviour change
More info
Mykola Pechenizkiy
-
Enhancing Reconstructive Surgery Decision-Making
The goal of this project would be to come up with a transformer or any other smart solution to (in a one sentence oversimplified description) find mappings between an image of the current patient condition, possible surgery actions and preferred outcome image. A more detailed …
More info
Mykola Pechenizkiy
-
Implementing inference algorithms for choice functions
In recent years, imprecise-probabilistic choice functions have gained growing interest, primarily from a theoretical point of view. These versatile and expressive uncertainty models have demonstrated their capacity to represent decision-making scenarios that extend beyond simple pairwise comparisons of options, accommodating situations of indecision as …
Arthur van Camp
More info
Cassio de Campos
-
Generative Random Forests: The Next Level
The work on generative random forests has started, but there is a long way to make them practical. This project aims at studying the drawbacks of such models and improving them with better ensemble ideas, gradient boosting, and/or other techniques already employed with decision …
More info
Cassio de Campos
-
Probabilistic Circuits versus Bayesian networks
This project aims to compare two different types of generative models: tractable probabilistic circuits and Bayesian networks of bounded tree-width, and potentially have tools to translate between them (when possible). Probabilistic circuits have been recently applied to a number of tasks, but there is …
More info
Cassio de Campos
-
Hybrid Bayesian networks
This internal project aims at developing and testing (for example in classification tasks) a generative model based on probabilistic graphical models for domains with continuous and categorical variables. We want to learn both the graph structure and parameters of such models while constraining their …
More info
Cassio de Campos
-
Synthetic data generation for causal learning
An arguably major difficulty for improving causal inferences is the lack of availability of data. While observational data are abundant, interventional data are not. This internal project aims at creating software tools to generate data that can be useful for testing causal learning approaches. …
More info
Cassio de Campos
-
Scalable Implementation of Probabilistic Circuits
This internal project aims at designing and development a usable software package for learning and reasoning with probabilistic circuits. Probabilistic circuits are models which can represent complicated mixture models and their computation circuit can be wide and deep. Because they have a structure which …
More info
Cassio de Campos
-
Algorithms for forward irrelevance with choice functions
In recent years, imprecise-probabilistic choice functions have gained growing interest, primarily from a theoretical point of view. These versatile and expressive uncertainty models have demonstrated their capacity to represent decision-making scenarios that extend beyond simple pairwise comparisons of options, accommodating situations of indecision as …
Arthur van Camp
More info
Cassio de Campos
-
Concepts of independence for choice functions
In recent years, imprecise-probabilistic choice functions have gained growing interest, primarily from a theoretical point of view. These versatile and expressive uncertainty models have demonstrated their capacity to represent decision-making scenarios that extend beyond simple pairwise comparisons of options, accommodating situations of indecision as …
Arthur van Camp
More info
Cassio de Campos
-
Local inference algorithms for choice functions
In recent years, imprecise-probabilistic choice functions have gained growing interest, primarily from a theoretical point of view. These versatile and expressive uncertainty models have demonstrated their capacity to represent decision-making scenarios that extend beyond simple pairwise comparisons of options, accommodating situations of indecision as …
Arthur van Camp
More info
Cassio de Campos
-
Interventional Whittle Sum-Product Networks
Whittle sum-product networks [1] model the joint distribution of multivariate time series by leveraging the Whittle approximation, casting the likelihood in the frequency domain, and place a complex-valued sum-product network over the frequencies. The conditional independence relations among the time series can then be …
More info
Devendra Dhami
-
Dynamic Knowledge Graph Embeddings
Knowledge graph embeddings are an important area of research inside machine learning and has become a necessity due to the importance of reasoning about objects, their attributes and relations in large graphs. There have been several approaches that have been explored and can be …
More info
Devendra Dhami
-
Preventing Beam Pollution: Defining an Empirical Protocol to Improve Beam Search Lattice Traversal
See PDF
More info Wouter Duivesteijn
Wouter Duivesteijn
-
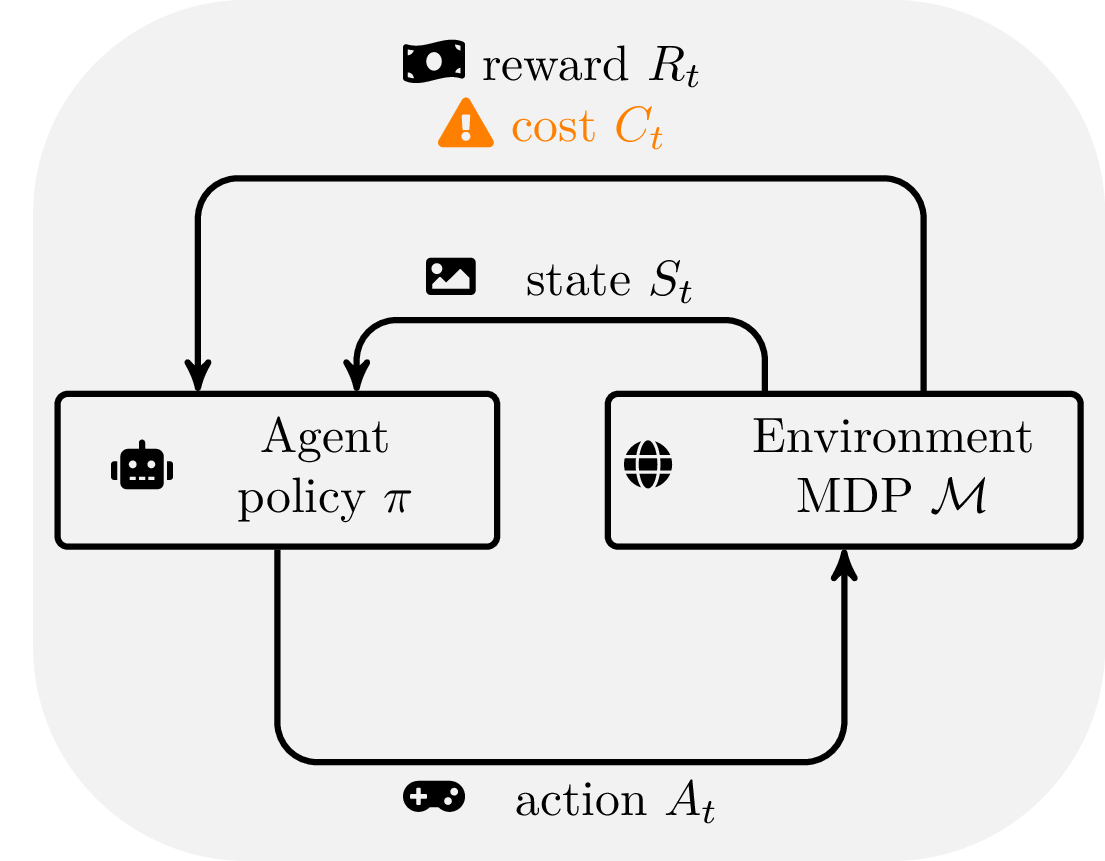
Safe reinforcement learning with decision transformers
Safety is a core challenge for the deployment of reinforcement learning (RL) in real-world applications [1]. In applications such as recommender systems, this means the agent should respect budget constraints [2]. In this case, the RL agent must compute a policy condition of the …
More info
Thiago Simão
-
Learning Decision Trees to Reduce the Sample Complexity of Offline Reinforcement Learning
Reinforcement Learning (RL) deals with problems that can be modeled as a Markov decision process (MDP) where the transition function is unknown. When an arbitrary policy was already in execution, and the experiences with the environment were recorded in a dataset, an offline RL …
More info
Thiago Simão
-
Reinforcement Learning for Configurable Systems
Nowadays, most software systems are configurable, meaning that we can tailor the settings to the specific needs of each user. Furthermore, we may already have some data available indicating each user's preferences and the software's performance under each configuration. This way, we can compute …
More info
Thiago Simão
-
Deriving Valuation Bases to Expand GP-Growth to More EMM Model Classes
See PDF
More info
Wouter Duivesteijn
-
Surveying to Bring Order in the Jungle of Supervised Local Pattern Mining Implementations
See PDF
More info
Wouter Duivesteijn
-
Expanding Exceptional Model Mining on Unstructured Data
See PDF. As attachment, see also https://wwwis.win.tue.nl/~wouter/MSc/Niels.pdf
More info
Wouter Duivesteijn
-
Finding the Curse of Dimensionality Sweet Spot Between Traditional Clustering and Deep Clustering
See PDF
Wouter Duivesteijn
More info
Sibylle Hess
-
Pimp my BUS: Improving a Minicluster-based Deterministic Pattern Sampling Algorithm for Exceptional Model Mining
See PDF. As attachment, see also https://wwwis.win.tue.nl/~wouter/MSc/Bart.pdf
More info
Wouter Duivesteijn
-

Topics in Deep Clustering
Deep clustering is a well-researched field with promising approaches. Traditional nonconvex clustering methods require the definition of a kernel matrix, whose parameters vastly influence the result, and are hence difficult to specify. In turn, the promise of deep clustering is that a feature transformation …
More info
Sibylle Hess
-
A Counterpart of SQL for Matrices
Most commercial databases are relational and use SQL to query the data. Often, however, data is not relational. Indeed, data scientists often deal with matrices instead of relations. A counterpart of SQL for the matrices is therefore needed, and initial progress has been reported …
More info
Robert Brijder
-
Programming Database Theory: Using a theorem prover to formalize database theory
Proving a theorem is similar to programming: in both cases the solution is a sequence of precise instructions to obtain the output/theorem given the input/assumptions. In fact, there are programming languages such as Lean, Coq, and Isabelle that can be used to prove theorems. …
More info
Robert Brijder
-
Peer-to-peer Federated Learning
--update--: This project is now taken by Davis EisaksThe goal of this project is to study how to train a machine learning model in a gossip-based approach, where if two devices (e.g smartwatches) pass each other in the physical space, they could exchange part of …
Mykola Pechenizkiy
More infoTDTim d'Hondt -
Bayesian Federated Learning using node-based BNNs.
Node-based BNNs assign latent noise variables to hidden nodes of a neural network. By restricting inference to the node-based latent variables, node stochasticity greatly reduces the dimension of the posterior. This allows for inference of BNNs that are cheap to compute and to communicate, …
Mykola Pechenizkiy
More infoTDTim d'Hondt -
ML projects at ASML
ASML has recently re-confirmed there two projects; a couple more will likely be confirmed in the coming weeksXAI in Exceptional Model Mining (--- update --- this project is taken by Yasemin Yasarol)In the semiconductor industry there are different, diverse and unique failure modes that impact …
Mykola Pechenizkiy
More infoTTtbc -
ML projects at Floryn
--- update --- These projects are no longer available. Theonymfi Anogeianaki will work on FairML.1. Bayesian inferenceWe have been doing ‘traditional’ machine learning for years now at Floryn but never investigated Bayesian modeling. We currently make use of probability measures that come from our (frequentist) machine learning …
More info
Mykola Pechenizkiy
-
Computational Complexity of Probabilistic Circuits
This internal project aims at studying and devising new bounds for the computational complexity of inferences in probabilistic circuits and their robust/credal counterpart, including approximation results and fixed-parameter tractability. It requires mathematical interest and good knowledge of theory of computation. This is a theoretical …
More info
Cassio de Campos
-
Learning Bayesian Networks in a Single Step
This internal project aims at implementing a new approach to learning the structure and parameters of Bayesian networks. It is mostly an implementation project, as the novel ideas are already established (but never published, so the approach is novel). It requires high expertise in …
More info
Cassio de Campos
-
Personalized research project in graph data management
This is a wildcard for projects in (knowledge) graph data management.If you took EDS (Engineering Data Systems) and liked what we did there, we offer research+engineering projects in the scope of our database engine AvantGraph (AvantGraph.io). Topics include (but not limited to):- graph query …
Nick Yakovets
More info Bram van de Wall
Bram van de Wall
-
Continual Structure from Motion
Autonomous vehicles and robots need 3D information such as depth and pose to traverse paths safely and correctly. Classical methods utilize hand-crafted features that can potentially fail in challenging scenarios, such as those with low texture [1]. Although neural networks can be trained on …
Bahram Zonooz
More info
Elahe Arani
-
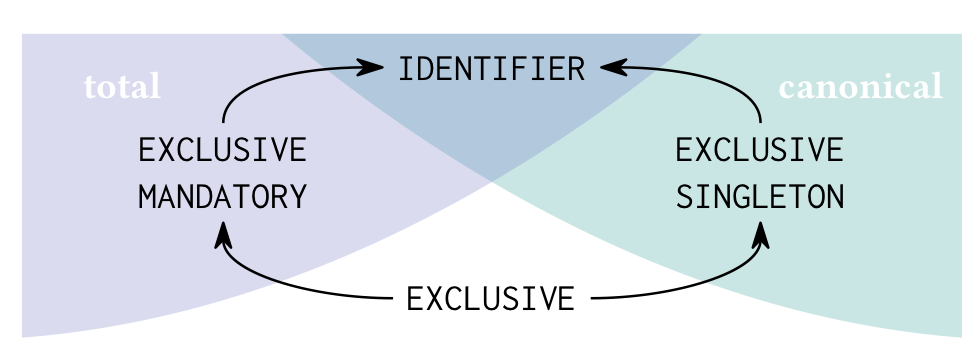
Schema language engineering in AvantGraph
Schema languages are critical for data system usability, both in terms of human understanding and in terms of system performance [0]. The property graph data model is part of the upcoming ISO standards around graph data management [4]. Developing a standard schema language for …
More info
George Fletcher
-

Diversifying attention through randomization in sparse neural networks training
Context of the work: Deep Learning (DL) is a very important machine learning area nowadays and it has proven to be a successful tool for all machine learning paradigms, i.e., supervised learning, unsupervised learning, and reinforcement learning. Still, the scalability of DL models is …
Mykola Pechenizkiy
More info Ghada Sokar
Ghada Sokar
-
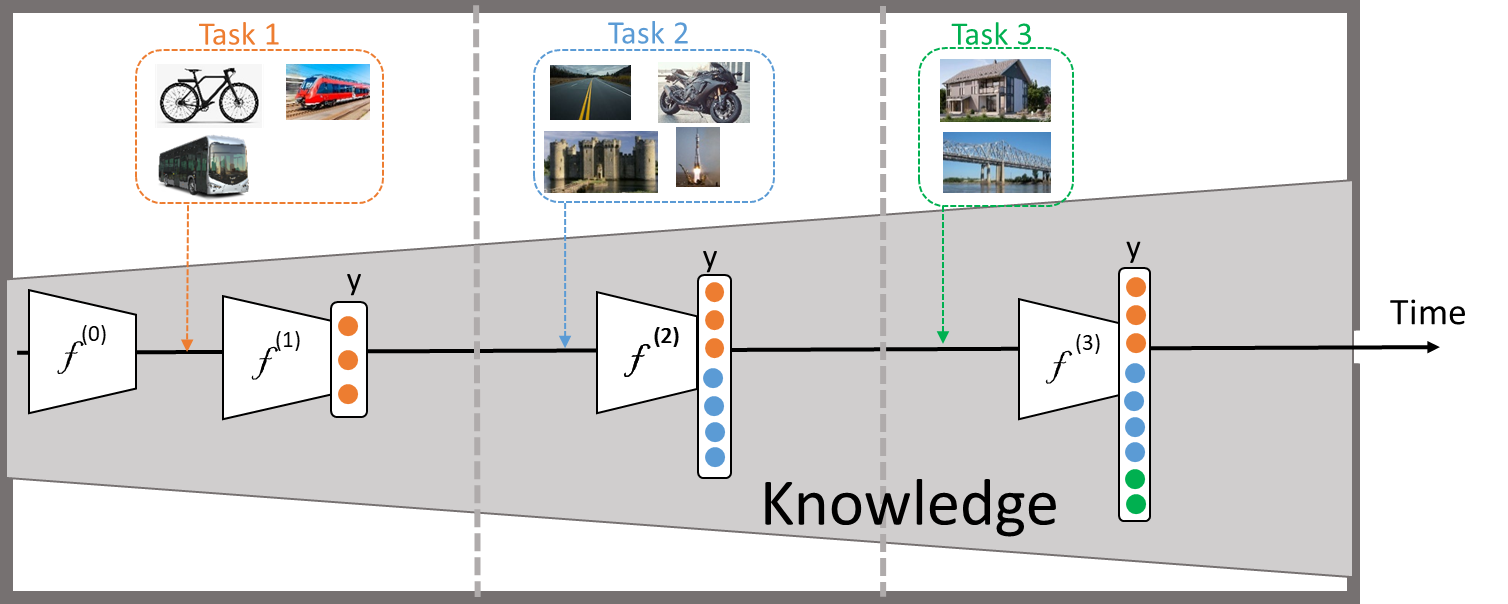
Topics in Continual Lifelong Learning
Nowadays, data changes very rapidly. Every day new trends appear on social media with millions of images. New topics rapidly emerge from the huge number of videos uploaded on Youtube. Attention to continual lifelong learning has recently increased to cope with this rapid data …
Mykola Pechenizkiy
More info
Ghada Sokar
-
Multi-modal Representation Learning and Applications
With the rapid development of multi-media social network platforms, e.g., Instagram, Tiktok, etc., more and more content is generated in the multi-modal format rather than pure text. This brings new challenges for researchers to analyze the user generated content and solve some concrete problems …
 Yulong Pei
More info
Yulong Pei
More info Tianjin Huang
Tianjin Huang
-
Architectural Analysis of Vision Transformers in Continual Learning
Deep neural networks (DNN) deployed in the real world are frequently exposed to non-stationary data distributions and required to sequentially learn multiple tasks. This requires that DNNs acquire new knowledge while retaining previously obtained knowledge. However, continual learning in DNNs, in which networks are …
Elahe Arani
More info
Bahram Zonooz
-
Human Visual System Inspired Mechanisms for Data Curation
Every second, around 107 to 108 bits of information reach the human visual system (HVS) [IK01]. Because biological hardware has limited computational capacity, complete processing of massive sensory information would be impossible. The HVS has therefore developed two mechanisms, foveation and fixation, that preserve perceptual performance …
Bahram Zonooz
More info
Elahe Arani
-
Human Visual System Inspired Mechanisms for Interpretability
Every second, around 107 to 108 bits of information reach the human visual system (HVS) [IK01]. Because biological hardware has limited computational capacity, complete processing of massive sensory information would be impossible. The HVS has therefore developed two mechanisms, foveation and fixation, that preserve perceptual performance …
Elahe Arani
More info
Bahram Zonooz
-
Human Visual System Inspired Mechanisms for Video Action Recognition/Prediction
Every second, around 107 to 108 bits of information reach the human visual system (HVS) [IK01]. Because biological hardware has limited computational capacity, complete processing of massive sensory information would be impossible. The HVS has therefore developed two mechanisms, foveation and fixation, that preserve perceptual …
Bahram Zonooz
More info
Elahe Arani
-
Online knowledge distillation for self-supervised learning
Self-supervised learning [1, 2] solves pretext prediction tasks that do not require annotations in order to learn feature representations. Recent empirical research has demonstrated that deeper and wider models benefit more from task-agnostic use of unlabeled data than their smaller counterparts; i.e., smaller models …
Bahram Zonooz
More info
Elahe Arani
-
Cardinality estimation for factorized query processing
It is well-known that processing of complex analytical queries over large graph datasets introduces a major pain point - runtime memory consumption. To address this, recently, a method based on factorized query processing (FQP) has been proposed. It has been shown that this method …
More info
Nick Yakovets
-

Deep Clustering: Simultaneous Optimization of Representations and Clustering
Deep clustering is a well-researched field with promising approaches. Traditional nonconvex clustering methods require the definition of a kernel matrix, whose parameters vastly influence the result, and are hence difficult to specify. In turn, the promise of deep clustering is that a feature transformation …
More info
Sibylle Hess
-
Building benchmarks for modern graph databases
There exists a wide variety of benchmarks available for graph databases: both synthetic and real-world-based. However, one important problem with current state of the art in graph database benchmarking is that all of the existing benchmarks are inherently based on workloads from relational databases, …
More info
Nick Yakovets
-
Achieving main-memory query processing performance on secondary storage on graph query workloads
Since DRAM is still relatively expensive and contemporary graph database workloads operate with billion-node-scale graphs, contemporary graph database engines still have to rely on secondary storage for query processing. In this project, we explore how novel techniques such as variable-page sizes and pointer swizzling can …
Nick Yakovets
More info
Bram van de Wall
-
Fairness-aware Influence Minimization for Combating Fake News
— completed —Influence blocking and fake news mitigation have been the main research direction for the network science and data mining research communities in the past few years. Several methods have been proposed in this direction [1]. However, none of the proposed solutions has …
Mykola Pechenizkiy
More info Akrati Saxena
Akrati Saxena
-
Towards Cognitive-inspired Adversarial Training Approach
Deep neural networks (DNN) are achieving superior performance in perception tasks; however, they are still riddled with fundamental shortcomings. There are still core questions about what the network is truly learning. DNNs have been shown to rely on local texture information to make decisions, …
Elahe Arani
More info
Bahram Zonooz
-
Generalizable, fair and explainable default predictors
— not available anymore —Context:Financial sector is a tightly regulated environment. All models used in the financial sector, are studied under the microscope of developers, validators, regulators, and eventually the end users – the clients, before these models can be deployed and used.To assess whether …
Mykola Pechenizkiy
More infoDDDLL -
Input Adaptive Inference for Semantic Segmentation
Neural networks typically consist of a sequence of well-defined computational blocks that are executed one after the other to obtain an inference for an input image. After the neural network has been trained, a static inference graph comprising these computational blocks is executed for …
Bahram Zonooz
More info
Elahe Arani
-

Explaining schema conformance for knowledge graphs: conformance reporting for WikiProjects members
Wikidata is an open collaboratively built knowledge base. In the Wikidata community groups of editors who share interest in specific topics form WikiProjects. As part of their regular work, members of WikiProjects would like to regularly test the conformance of entity data in Wikidata against schemas for entity classes. …
George Fletcher
More infoKUKatherine Thornton, Yale University (USA) -

Improving knowledge graph completeness with schemas: Wikidata and ShEx
In the collaboratively built knowledge base Wikidata some editors would appreciate suggestions of how to improve the completeness of items. Currently some community members use an existing tool, Recoin, described in this paper, to get suggestions of relevant properties to use to contribute additional statements. This process could …
George Fletcher
More infoKUKatherine Thornton, Yale University (USA) -
SIMD-based JSON data processing in a dynamic Language VM
The JSON data format is one of the most popular human-readable data formats, and is widely used in Web and Data-intensive applications. Unfortunately, reading (i.e., parsing) and processing JSON data is often a performance bottleneck due to the inherent textual nature of JSON. Recent …
More info Daniele Bonetta
Daniele Bonetta
-
ML-based compiler auto-tuning in GraalVM
Machine-learning based approaches [3] are increasingly used to solve a number of different compiler optimization problems. In this project, we want to explore ML-based techniques in the context of the Graal compiler [1] and its Truffle [2] language implementation framework, to improve the performance …
More info
Daniele Bonetta
-
Dynamic SQL query compilation in GraalVM
Data processing systems such as Apache Spark [1] rely on runtime code generation [2] to speedup query execution. In this context, code generation typically translates a SQL query to some executable Java code, which is capable of delivering high performance compared to query interpretation. …
More info
Daniele Bonetta
-
ML-based Profile-guided optimization in GraalVM
Profile-guided optimization (PGO) [1] is a compiler optimization technique that uses profiling data to improve program runtime performance. It relies on the intuition that runtime profiling data from previous executions can be used to drive optimization decisions. Unfortunately, collecting such profile data is expensive, …
More info
Daniele Bonetta
-
Sea-of-nodes graphs query and visualization
Language Virtual Machines such as V8 or GraalVM [3] use Graphs to represent code. One example Graph representation is the so-called Sea-of-nodes model [1]. Sea-of-nodes graphs of real-world programs have millions of edges, and are typically very hard to query, explore, and analyze. In …
More info
Daniele Bonetta
-
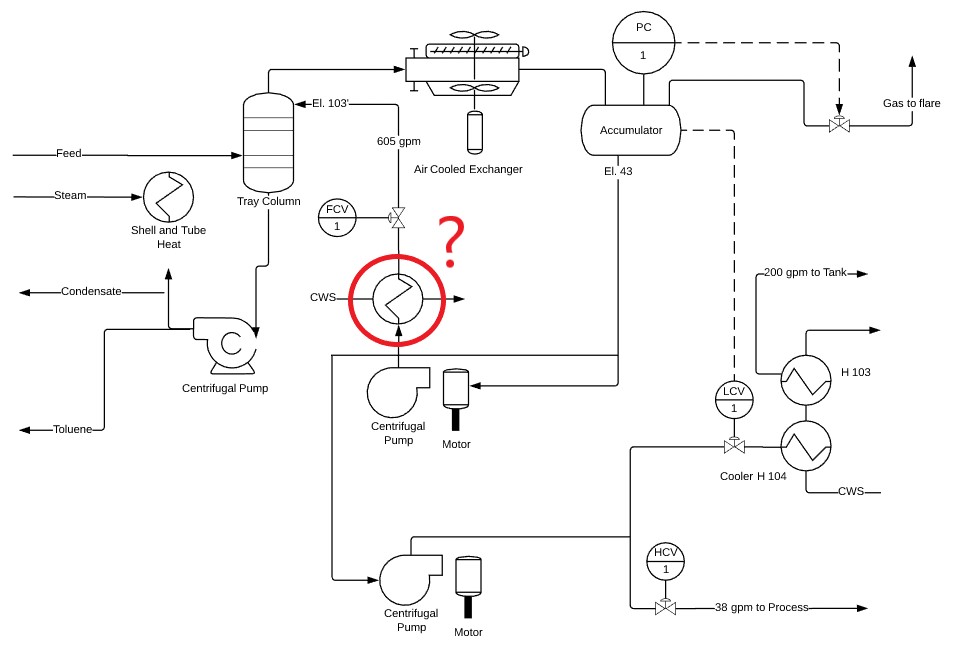
Robust symbol detection and recognition in piping and instrumentation diagrams
— not available anymore —Project description This project is concerned with the recognition of symbols of piping and process equipment together with the instrumentation and control devices that appear on piping and instrumentation diagrams (P&ID). Each item on the P&ID is associated with a pipeline. Piping …
Mykola Pechenizkiy
More info
Stiven Schwanz Dias
-
Battle of the credal networks: strong independence or forward irrelevance?
Bayesian networks are a popular model in AI. Credal networks are a robust version of Bayesian networks created by replacing the conditional probability mass functions describing the nodes by conditional credal sets (sets of probability mass functions). Next to their nodes, Bayesian networks are …
More info Erik Quaeghebeur
Erik Quaeghebeur
-
Fairness Analysis in Anomaly Detection
In anomaly detection, we aim to identify unusual instances in different applications, including malicious users detection in OSNs, fraud detection, and suspicious bank transaction detection. Most of the proposed anomaly detection methods are dependent on network structure as some specific structural pattern can convey …
Mykola Pechenizkiy
More info
Akrati Saxena
-
Curiosity driven fairness in Reinforcement learning
Reinforcement learning (RL) is a computational approach to automating goal-directed decision making. In this project, we will use the framework of Markov decision processes. Fairness in reinforcement learning [1] deals with removing bias from the decisions made by the algorithms. Bias or discrimination in …
Mykola Pechenizkiy
More info Pratik Gajane
Pratik Gajane
-
Generate fair (pseudo) samples for reinforcement learning
Reinforcement learning (RL) is a computational approach to automating goal-directed decision making. Reinforcement learning problems use either the framework of multi-armed bandits or Markov decision processes (or their variants). In some cases, RL solutions are sample inefficient and costly. To address this issue, some …
Mykola Pechenizkiy
More info
Pratik Gajane
-
Causal perspective of fairness in reinforcement learning
Reinforcement learning (RL) is a computational approach to automating goal-directed decision making using the feedback observed by the learning agent. In this project, we will be using the framework of multi-armed bandits and Markov decision processes. Observational data collected from real-world systems can mostly …
Mykola Pechenizkiy
More info
Pratik Gajane
Assigned Projects (31)
-
Your neural network is secretly wasting capacity: why (not) compress it?Mar 2026
Please note this project is no longer available. We train ever larger and larger neural networks. However, several studies indicate that large parts of those large networks are not actually contributing to their performance. It has for example been shown that some layers and …
More info Hannah Pinson
Hannah Pinson
-
Deep learning for solving PDEsMar 2026
Partial Differential Equations (PDEs) are the backbone of modern science and engineering, governing phenomena from climate modeling and drug discovery to aerospace design and seismic imaging. Solving these equations with classical numerical methods can be computationally very intensive. More recently, numerous neural network methods …
Hannah Pinson
More infoPAProf. Dr. Victorita Dolean-Maini (scientific computing) and Dr. Michael Abdelmalik (computational fluid dynamics) -
Deriving Upper Confidence Bounds to Expand Monte-Carlo Tree Search to More EMM Model ClassesMar 2026
See PDF
HQHongda QiMore info
Wouter Duivesteijn
-
Generating Missing At Random (MAR) data in Images; a Convolutional ApproachFeb 2026
See PDF
DWDavid Wolf
Wouter Duivesteijn
More info
Vlado Menkovski
-
Exceptional Gestalt Mining (EGM)Feb 2026
See PDF
KGKonstantin Georgiev
Wouter Duivesteijn
More infoTDThomas van Dijk -
Context-Aware Model-Based Offline Reinforcement LearningJan 2026
Offline Reinforcement Learning (RL) deals with the problems where simulation or online interaction is impractical, costly, and/or dangerous, allowing to automate a wide range of applications from healthcare and education to finance and robotics. However, learning new policies from offline data suffers from distributional …
More info
Maryam Tavakol
-
Efficient database infrastructure for librariesNov 2025
Database management systems for libraries (as in, institutions for lending books) need to satisfy a number of specific needs, in particular regarding the types of queries that need to be supported and regarding performance of the queries that are most often executed. In this …
More info
Robert Brijder
-
Reinforcement Learning under Dynamic Safety BoundsNov 2025
Safe Reinforcement Learning (Safe RL) typically assumes a fixed safety bound or cost threshold, constraining the agent’s behavior during training and evaluation. However, in many real-world applications (e.g., robotics, autonomous driving, or healthcare), safety requirements are not static. Regulatory limits, environmental constraints, or critical …
SGSarthak Goswami Tristan Tomilin
More info
Thiago Simão
Tristan Tomilin
More info
Thiago Simão
-
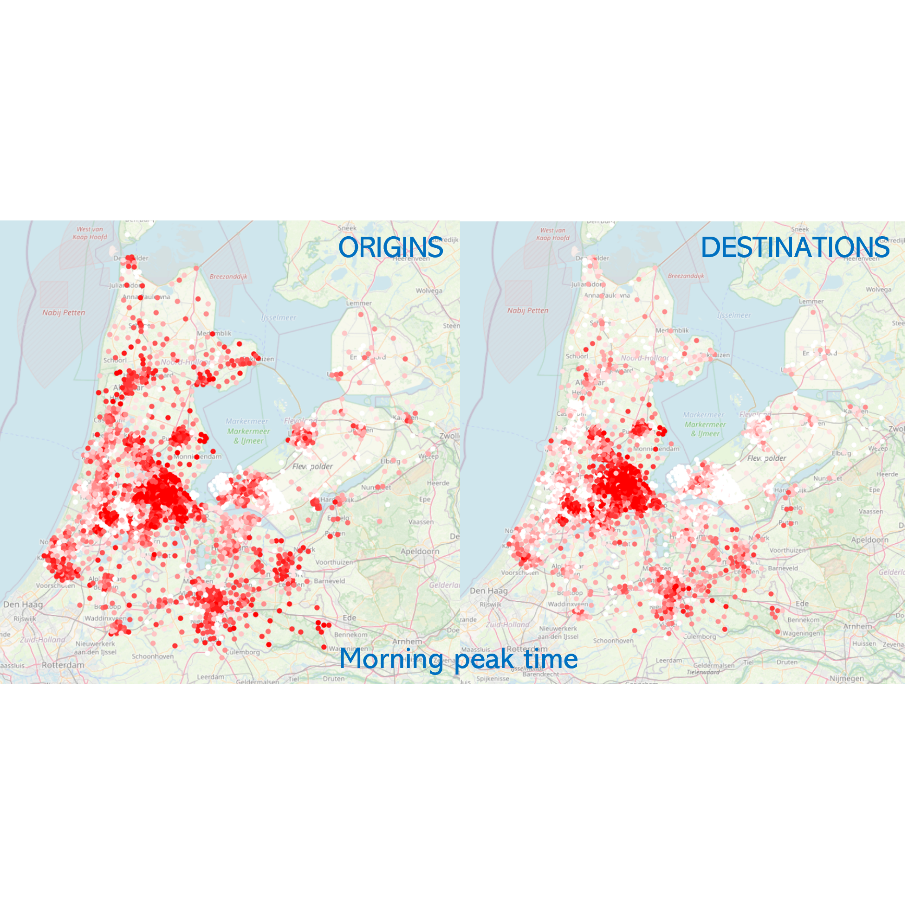
[Internship at TNO] Fair Resource Allocation in Car-free AreasNov 2025
Applications are now open and will remain open until a suitable candidate is found (details below). The XCARCITY program investigates how to facilitate and support the implementation of car-free areas in Amsterdam, Almere Pampus, and the Metropoolregio Rotterdam Den Haag.Car-free and car-low areas offer …
LRLorenzo RotaMore info
Thiago Simão
-
MedGPT – LLM/foundation models in healthcare & patient privacy (multiple projects)Oct 2025
Please note these projects are no longer availableWe have multiple graduation projects available within the context of the MedGPT project, a large European project focusing on the safe and ethical use of LLMs and foundation models in healthcare. For students interested in gaining a …
TTtMore info
Hannah Pinson
-
Reinforcement Learning with Many ConstraintsOct 2025
In this project, we study the development of reinforcement learning (RL) for applications with many constraints.Applying RL requires designing the reward function, which can be challenging in applications with many objectives. For instance, in autonomous driving, the RL agent should minimize the time to …
APAndrei PopoviciuMore info
Thiago Simão
-

Procedural 3D Environment Generation for Image-Based Reinforcement LearningSep 2025
As autonomous systems evolve, static simulation environments for training reinforcement learning agents increasingly fail to prepare algorithms for real-world variability. Procedural content generation (PCG) [5] in 3D environments offers a low-cost solution to automatically creating a near-infinite variety of dynamic training scenarios. This has the …
GHGiuseppe Hannen
Tristan Tomilin
More info
Thiago Simão
-
Multimodal Time Series Analysis for Out-of-Distribution GeneralizationSep 2025
Introduction Multimodal time series analysis is an emerging field that leverages multiple data sources to enhance predictive modeling. In retail, time series data often includes numerical sales records and image-based product information, providing a rich dataset for forecasting demand and understanding customer behavior. However, …
RRRaneeMore info Amy Deng
Amy Deng
-
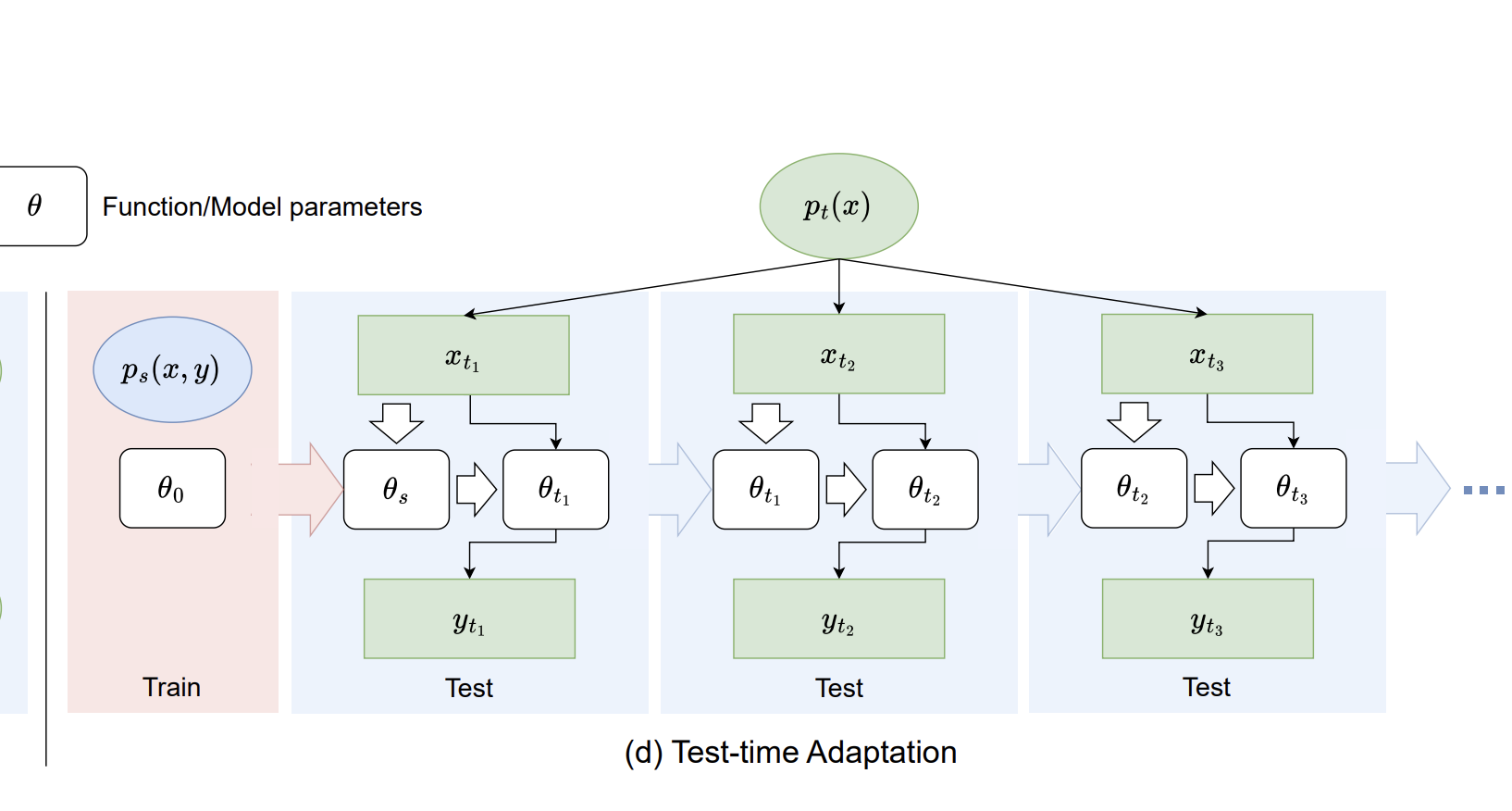
Learning to Adapt: Test-Time Normalization for Non-Stationary Time Series ForecastingSep 2025
Background & Motivation:In real-world time series forecasting tasks—such as energy demand, traffic, or financial signals, data distributions often shift over time. These non-stationarities (e.g., changes in trend, seasonality, or noise) can significantly degrade model performance at test time.Recent methods like RevIN (Reversible Instance Normalization) …
NWNaijia WanMore info
Amy Deng
-
Building a drought impact database for the Netherlands and cross-border catchmentsAug 2025
Overview Help us build a structured, high-quality historical database of drought impacts in the Netherlands using NLP on newspaper archives. You'll extract detailed information from Dutch and selected Belgian/German news sources (areas influencing the Rhine, Meuse, and Vecht river systems). The goal is to …
Erik Quaeghebeur
More infoHKHans Korving (Deltares) -
A Matrix Factorization approach to Exceptional Model MiningAug 2025
Exceptional Model Mining aims to identify subgroups in the dataset that behave somehow exceptionally. It differs from a clustering approach since subgroups may overlap; not all data points are assigned to a cluster. However, consequently, the list of subgroups often contains many similar, redundant …
GKGheytuli, Kasra Rianne Schouten
More info
Sibylle Hess
Rianne Schouten
More info
Sibylle Hess
-
Autonomous Apple Harvesting via Reinforcement LearningJun 2025
VBTI is an AI engineering company specializing in developing Deep Learning solutions for industries such as agriculture and manufacturing. This project aims at developing Autonomous Apple Harvesting, building on an existing proof-of-concept previously created by the company. The initial implementation utilized an object detection …
Maryam Tavakol
More infoIKIllya Kaynov -

Benchmarking a Multimodal Time Series DatasetJun 2025
1. IntroductionMultimodal time series datasets are increasingly valuable in finance, healthcare, industrial monitoring, and other domains. However, their availability remains limited, and standardized benchmarking is underexplored. This project benchmarks a new multimodal time series dataset from the company WAIR, assessing its unique characteristics and …
ZTZhang TianyiMore info
Amy Deng
-
Safe Contrastive Imitation LearningApr 2025
MotivationIn safety-critical domains such as autonomous driving, healthcare robotics, and industrial automation, it is imperative for autonomous agents to not only perform tasks efficiently but also safely. Traditional imitation learning enables agents to learn behaviors by mimicking expert demonstrations. However, these methods often overlook …
ACAnnika Möller Chandiramani
Tristan Tomilin
More info
Thiago Simão
-
Breeding Program Optimization via Offline Reinforcement LearningApr 2025
Crop breeding programs aim to develop new cultivars with desirable traits through controlled mating within a population, enhancing agricultural productivity while reducing land use, greenhouse gas emissions, and water consumption. However, these programs face challenges like long turnover times, complex decision-making, long-term goals, and climate …
Maryam Tavakol
More infoIAIoannis Athanasiadis -
Uncertainty Estimation in Model-Based Offline Reinforcement Learning using Random NetworksApr 2025
Offline Reinforcement Learning (RL) deals with the problems where simulation or online interaction is impractical, costly, and/or dangerous, allowing to automate a wide range of applications from healthcare and education to finance and robotics. However, learning new policies from offline data suffers from distributional …
More info
Maryam Tavakol
-
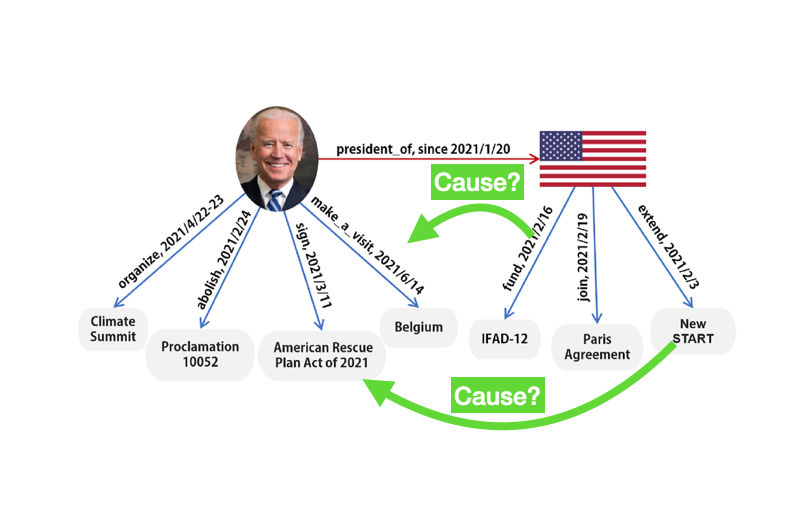
Mining Causal Relations Between Real-world Human EventsMar 2025
Motivation: The ACLED dataset (https://acleddata.com/knowledge-base/codebook/) provides a detailed record of political violence and protest events, capturing actors, timelines, and descriptions of the incidents. However, this rich data remains largely underutilized when it comes to understanding the causal relationships between events. While common knowledge graphs typically rely …
TLTianyuan LiuMore info
Amy Deng
-
Object-relational mapping for key-value databasesDec 2024
Object-relational mappers (ORM) like Django allow one to interact with a database in an object-oriented manner, and provide constructs for easy deployment of web-based applications that depend on a database. The underlying database of an ORM is typically a SQL database. It is unclear …
More info
Robert Brijder
-
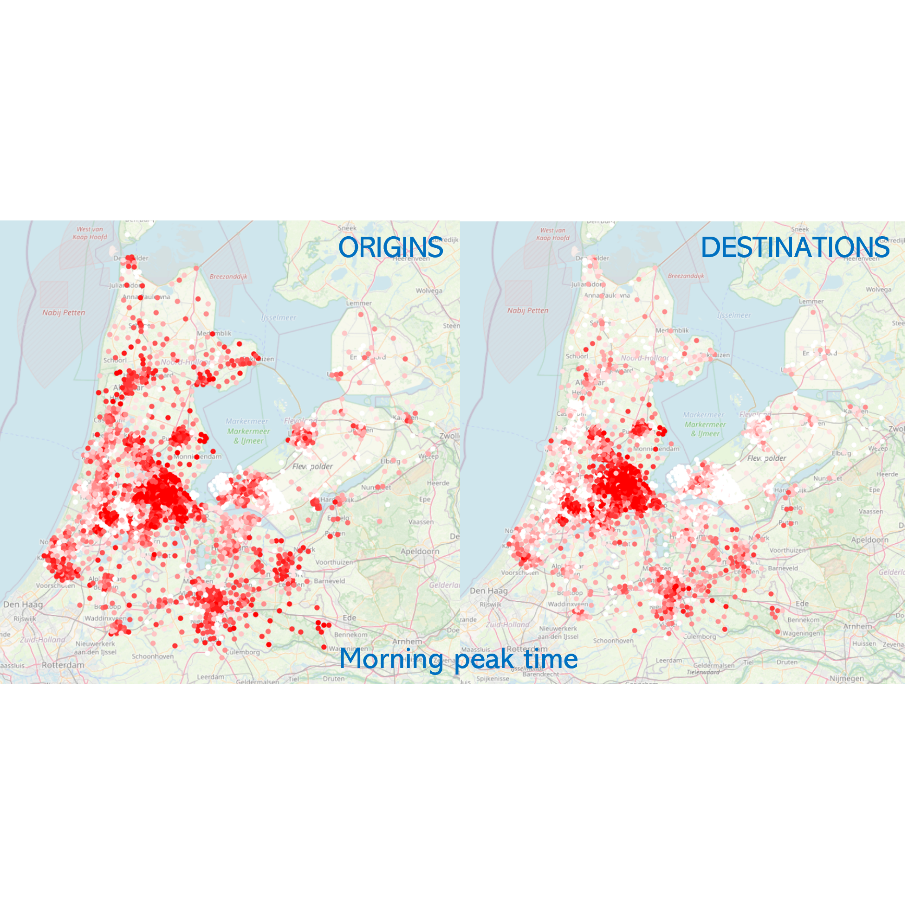
[Internship at TNO] Dynamic road space allocation with shared mobility hubsNov 2024
The XCARCITY project investigates how to facilitate and support implementation of car-free areas in Amsterdam, Almere Pampus and Metropoolregio Rotterdam Den Haag.Car-free and car-low areas offer many benefits by freeing up road space, reducing congestion and parking requirements, and generally contributing to increased livability …
DVDido Verstegen
Thiago Simão
More infoCPCanmanie T. Ponnambalam -

Reinforcement Learning for Contact-rich and Impact-aware Robotic TasksNov 2024
Reinforcement Learning (RL) [6] has achieved successful outcomes in multiple applications, including robotics [1]. A key challenge to deploying RL in such a scenario is to ensure the agent is robust so it does not lose performance even if the environment's geometry and dynamics …
More info
Thiago Simão
-

Dual arm manipulation of heavy objects with humanoid robots via reinforcement learningNov 2024
Motivation. Reinforcement Learning(RL; Sutton and Barto 2018) has achieved successful outcomes in multiple applications, including robotics(Kober, Bagnell, and Peters 2013). A key challenge to deploying RL in such a scenario is to ensure the agent is robust so it does not lose performance even …
More info
Thiago Simão
-
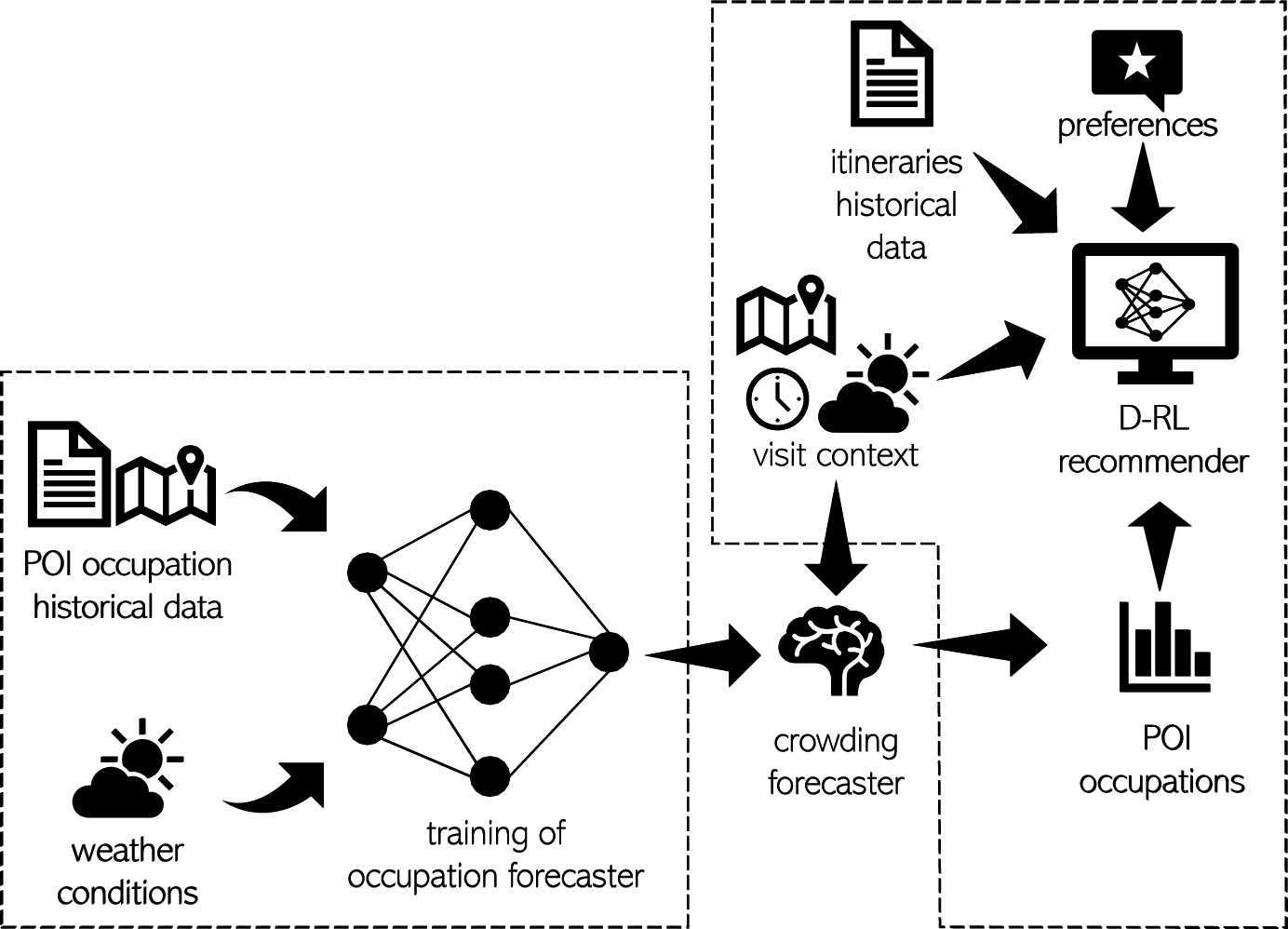
Multi-agent reinforcement learning for sustainable touristic recommender systemNov 2024
A touristic recommender system (TRS; Dalla Vecchia et al., 2024; Gaonkar et al., 2018; de Nijs et al., 2018) often provides to its users a sequence of recommendations instead of a single suggestion to optimize the user experience in the available time interval. Due …
PDPaul Dewez
Thiago Simão
More infoEQElisa Quintarelli -
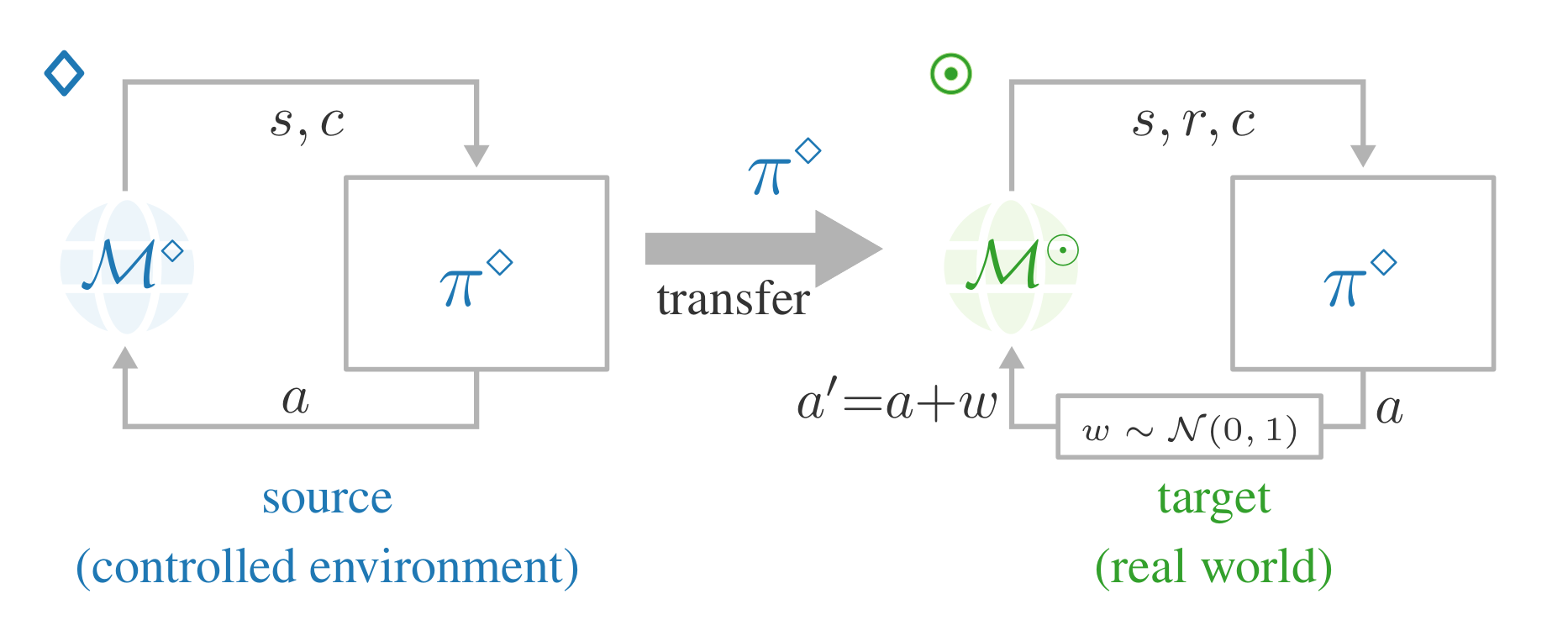
Adversarial attacks for safe transfer in reinforcement learningNov 2024
Safety is a paramount challenge for the deployment of autonomous agents. In particular, ensuring safety while an agent is still learning may require considerable prior knowledge (Carr et al., 2023; Simão et al., 2021). A workaround is to pre-train the agent in a similar …
CMCheuk Lam MoMore info
Thiago Simão
-

High-performance Safe RL BenchmarkingNov 2024
As AI systems become increasingly integral to critical sectors, ensuring their safety and reliability is essential. Reinforcement Learning (RL) is a prominent method that learns optimal behaviors through trial-and-error interactions with a dynamic environment. Yet, the stakes are high: in physical settings, a wrong …
MBMourad Boustani
Tristan Tomilin
More info
Thiago Simão
-
Understanding deep learning: efficient retraining of networksJul 2024
Recent work has shown that neural networks, such as fully connected networks and CNNs, learn to distinguish between classes from broader to finer distinctions between those classes [1,2] (see Fig. 1). Figure 1: Illustration of the evolution of learning from broader to finer distinctions between …
More info
Hannah Pinson
-
Understanding deep learning: the initial learning rateJul 2024
This project is finished/closed. While deep learning has become extremely important in industry and society, neural networks are often considered ‘black boxes’, i.e., it is often believed that it is impossible to understand how neural networks really work. However, there are a lot of …
More info
Hannah Pinson
Finished Projects (43)
-
AI for histopathology of melanomaFeb 2026
BackgroundMelanoma is a form of skin cancer that originates in melanin-producing cells known as melanocytes. While other skin cancer types occur more frequently, melanoma is most dangerous due to the high likelihood of metastasis if not treated early. The incidence rate of melanoma has …
Sibylle Hess
More infoMVMitko Veta -
Survey and evaluation of IoT hubs for data ingestionFeb 2026
Data ingestion in IoT networks frequently utilizes a software called 'IoT hub'. In this project you will: (a) consider the requirements of a large organization (Naturalis), for ingesting data from their IoT network to their Databricks platform, (b) examine the usefulness of existing IoT …
More info
Odysseas Papapetrou
-
Exceptional Gestalt Mining (EGM)Feb 2026
See PDF
PRPim Rietjens
Wouter Duivesteijn
More infoTBThomas C. van Dijk, Ruhr-Universität Bochum -
[Closed] (PwC) LLMs for Data Analysis PipelinesJan 2026
LLM has the potential to make data more accessible to a non-technical audience through prompt-based analytics. It also has the potential to help make engineering teams more efficient by quickly getting a first draft of a data pipeline.Both of these applications hinge on appropriate …
More info
Bart Engelen
-
[Closed] (PwC) Enhancing Anomaly Detection: Integrating User ExplainabilityDec 2025
PwC developed an unsupervised Transformer-based anomaly detection tool to enhance insights into machine functionality in factories by analyzing machinery timeseries sensor data. However, the current solution lacks explainability for why certain time windows are flagged as anomalous. Root cause algorithms, such as Bayesian inference, …
More info
Bart Engelen
-
[Closed] (PwC) Question bank generator for Applied GenAIDec 2025
(PwC) Question bank generator for Applied GenAI PwC has developed several GenAI applications using models that have been trained on a large corpus of text and can retrieve relevant parts of that corpus when prompted by a user's questions (known as RAG-LLMs). Though many …
More info
Bart Engelen
-
Detection of high-order correlations in health dataNov 2025
Correlations are instrumental for our understanding on complex systems. For example, after years of studying scientists know that smoking is correlated to cancer. There are however some more nuanced correlations, which are more difficult to detect. These are called ‘deep correlations’ or ‘high-order correlations’. …
More info
Odysseas Papapetrou
-
Data access for ambulance care personnelOct 2025
When an ambulance is dispatched to assist a patient, it would be highly beneficial for ambulance personnel to have controlled access to the patient’s medical data stored in their general practitioner’s (GP) database. Currently, such access is not feasible due to both technical and …
More info
Odysseas Papapetrou
-
Improved monitoring for home-care patientsOct 2025
The plethora of cheap smart devices (particularly smart phones and smart watches) makes it promising for improved monitoring of home-care patients. In this thesis you will investigate the key involved challenges and study and propose technical solutions, using big data technologies (the contents of …
More info
Odysseas Papapetrou
-

Enhancing Real-World Imitation Learning with Reinforcement LearningSep 2025
This TU/e master project is setup in collaboration with a robotics start-up in Eindhoven.Company OverviewTeleOperation Services is an innovative company based in Woensel-Noord, Eindhoven. Our cutting-edge AI-driven system empowers robotic arms to imitate tasks and perform them independently with human-like finesse and speed. Through …
QBQuint Bakens
Bram Grooten
More info
Thiago Simão
-
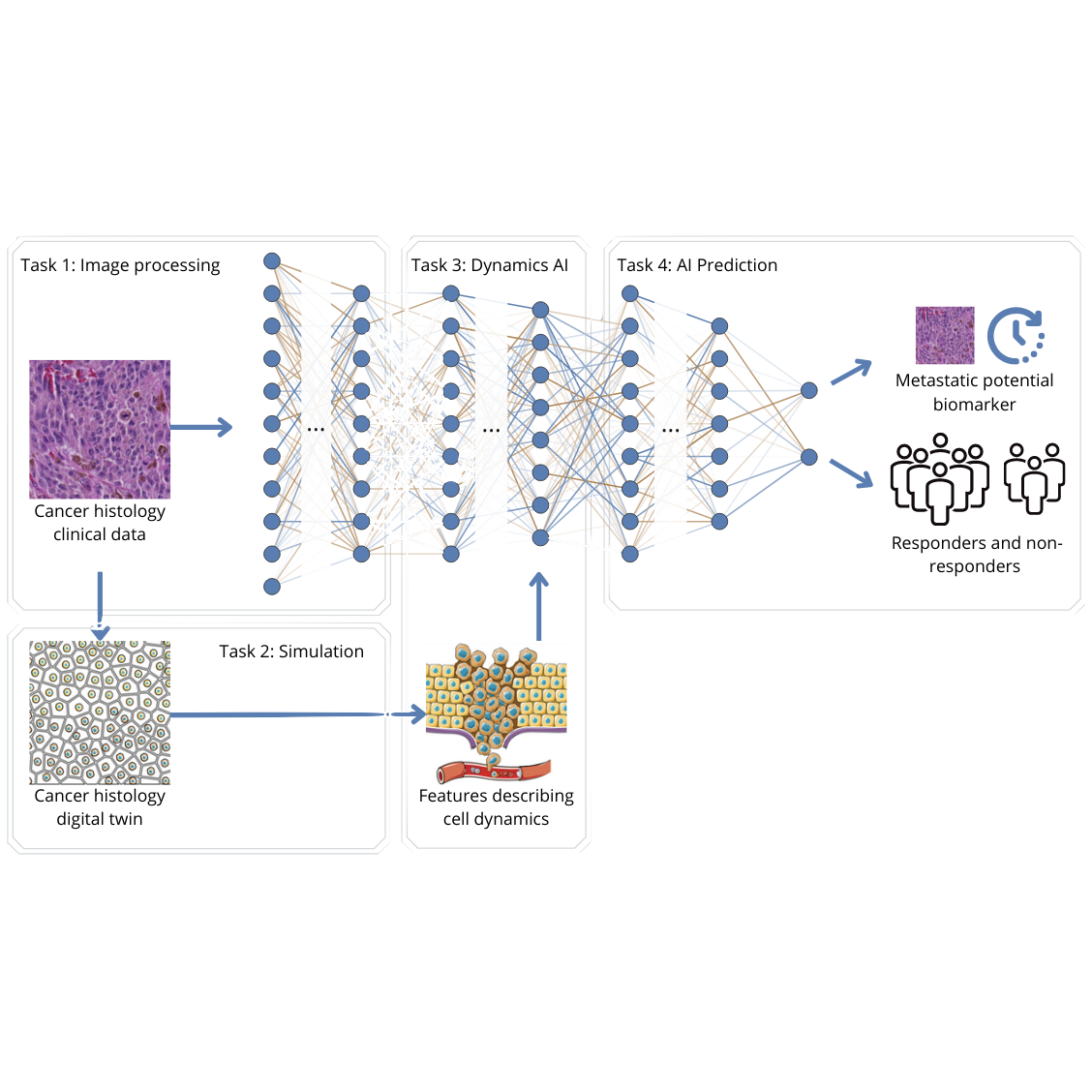
Physics Informed AI for improved cancer prognosisAug 2025
In order to metastasize, cancer cells need to move. Estimating the ability for cells to move, i.e. their dynamics, or so-called migration potential, is a promising new indicator for cancer patient prognosis (overall survival) and response to therapy. However, predicting the migration potential from …
BMBram Meijer
Sibylle Hess
More infoSVSecondary supervisors could be Liesbeth Janssen or Mitko Vetka. -
Leveraging LLMs to create multimodal explanationsAug 2025
AI is currently being used in a wide range of applications. However, most AI systems operate as a black box, meaning that it is hard to understand how an AI system comes to its predictions. Explainable AI (XAI) is a research field that tries …
Sibylle Hess
More infoWMWil Michiels -
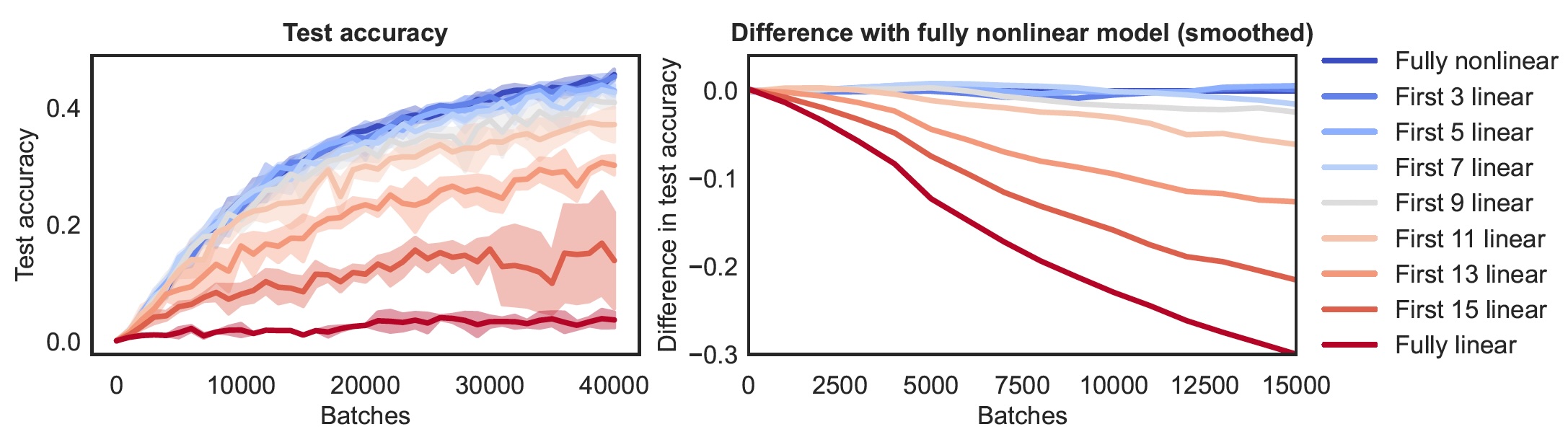
Understanding deep learning – exploring the development of complexity in neural networks over depth and timeMay 2025
Introduction: When we train deep, nonlinear neural networks, we often assume that the applied transformations at every layer are effectively nonlinear. Earlier work (Kalimeris et al., 2019)has shown that in the beginning of training, the complete function that deep, nonlinear networks implement is close …
Hannah Pinson
More info Aurélien Boland
Aurélien Boland
-
Lagged multivariate correlationsMay 2025
Correlations are extensively used in all data-intensive disciplines, to identify relations between the data (e.g., relations between stocks, or between medical conditions and genetic factors). The 'industry-standard' correlations are pairwise correlations, i.e., correlations between two variables. Multivariate correlations are correlations between three or more …
More info
Odysseas Papapetrou
-
Detection of similarities and correlations in multidimensional time seriesMay 2025
Correlations are extensively used in all data-intensive disciplines, to identify relations between the data (e.g., relations between stocks, or between medical conditions and genetic factors). Most algorithms consider one-dimensional time series. For example, in the context of finance, the time series might represent the …
More info
Odysseas Papapetrou
-
Discovery and maintenance of heavy hitters over sliding windows, in a distributed environment.May 2025
Synopses are extensively used for summarizing high-frequency streaming data, e.g., input from sensors, network packets, financial transactions. Some examples include Count-Min sketches, Bloom filters, AMS sketches, samples, and histogram. This project will focus on designing, developing, and evaluating synopses for the discovery of heavy …
More info
Odysseas Papapetrou
-
Multivariate correlations for data cleaningMay 2025
Correlations are extensively used in all data-intensive disciplines, to identify relations between the data (e.g., relations between stocks, or between medical conditions and genetic factors). The 'industry-standard' correlations are pairwise correlations, i.e., correlations between two variables. Multivariate correlations are correlations between three or more variables. …
More info
Odysseas Papapetrou
-
Language Agents for Playing Card GamesDec 2024
The project is a pioneering initiative that combines Natural Language Processing (NLP) and Reinforcement Learning (RL) methodologies to create intelligent agents capable of understanding natural language instructions and participating in playing card games. This project aims to develop AI-driven agents that not only comprehend …
 Meng Fang
More info
Meng Fang
More info Yudi Zhang
Yudi Zhang
-
Playing Text-based Games with Large Language ModelsDec 2024
The project aims to explore the utilization of sophisticated language models in the domain of text-based games. This endeavor seeks to harness the capabilities of large language models, such as GPT (Generative Pre-trained Transformer), in the context of interactive narratives, text adventures, and other …
Meng Fang
More info
Yudi Zhang
-

Sustainable Large Language ModelsDec 2024
Project description:Large Language Models (LLMs) are deep-learning models that achieve state-of-the-art performance in many NLP tasks. They typically consist of billions of weights. As a result, expressing weights in float32 leads to models of size at least 1GB. Such large models cannot be easily …
DHDalton HarmsenMore info Jakub Tomczak
Jakub Tomczak
-

Large Language Models with Knowledge GraphsDec 2024
Project description:Large Language Models (LLMs) are well-known for knowledge acquisition from large-scale corpus and for achieving SOTA performance on many NLP tasks. However, they can suffer from various issues, such as hallucinations, false references, made-up facts. On the other hand, Knowledge Graphs (KGs) can …
JLJasper LindersMore info
Jakub Tomczak
-

Multi-Agent Reinforcement Learning for Cooperative TasksDec 2024
Multi-Agent Reinforcement Learning (MARL) is a field in artificial intelligence where multiple agents learn to make decisions in an environment through reinforcement learning. In the context of cooperative tasks, it involves agents working together to achieve common goals, sharing information and coordinating their actions …
LBLuka van den Boogaard
Meng Fang
More info
Tristan Tomilin
-
Large language Model Based Chatbots and their ApplicationsDec 2024
In recent years, large language models have revolutionized how machines understand and generate human-like text, offering profound implications for chatbot technology. This thesis proposes a deep exploration into the capabilities of these models within chatbot applications, aiming to enhance how they mimic human conversational …
Meng Fang
More info Jiaxu Zhao
Jiaxu Zhao
-
Curriculum Learning for Constrained Reinforcement Learning in Contextual MDPsOct 2024
Sample complexity is one of the core challenges in reinforcement learning (RL)[1]. An RL agent often needs orders of magnitude more data than supervised learning methods to achieve a reasonable performance. This clashes with problems with safety requirements, where the agent should minimize the …
KTKelvin ToonenMore info
Thiago Simão
-

Sustainable Diffusion ModelsAug 2024
Project description:Diffusion Models are deep-learning models that achieve state-of-the-art performance in many image synthesis tasks. They are typically parameterized with UNets and consist of billions of weights. Expressing their weights in float32 leads to models that cannot be easily deployed on edge devices (e.g., …
More info
Jakub Tomczak
-

Deep Generative Models for (Conditional) Molecule GenerationAug 2024
Project description:Generative AI has become one of the leading approaches to (conditional) molecule generation. Like Large Language Models can learn (to some degree) rules governing natural language, could Large Chemistry Models learn rules governing atoms (quantum chemistry)? This is the leading research question of …
SDSidney DamenMore info
Jakub Tomczak
-

Generative Object Detection Models for Mobile Robotics ApplicationsAug 2024
Project description:In the dynamic landscape of mobile robotics, object detection remains a foundational challenge, critical for enabling machines to interact intelligently with their surroundings. At Avular, a pioneering mobile robotics company in Eindhoven, we are excited to explore novel and innovative approaches in this …
DGDik van Genuchten
Jakub Tomczak
More infoBKBart Keulen -
(closed) Understanding deep learning: linear vs non-linear models and their dynamics of learningJul 2024
This project is finished/closed.While deep learning has become extremely important in industry and society, neural networks are often considered ‘black boxes’, i.e., it is often believed that it is impossible to understand how neural networks really work. However, there are a lot of aspects …
More info
Hannah Pinson
-

A feasibility study on automated database exercise generation with large language modelsJul 2024
Your lecturers here at the university spend a lot of time creating new exercises for our students, both for weekly assignments as for exams. If you extrapolate this to universities and professional training globally, this is a tremendous effort and use of time. It …
WAWillem Aerts
George Fletcher
More info Daphne Miedema
Daphne Miedema
-

Analyzing progression of question difficulty for SQL questions on Stack OverflowJul 2024
SQL is difficult to use effectively, and creates many errors. Error types and frequency in SQL have been analyzed by various researchers, such as Ahadi, Prior, Behbood and Lister, and Taipalus and Siponen. One method of problem solving that computer scientists apply is posting …
BWBert Wijnhoven
George Fletcher
More info
Daphne Miedema
-
On Neural Cellular AutomataJul 2024
The design of collective intelligence, i.e. the ability of a group of simple agents to collectively cooperate towards a unifying goal, is a growing area of machine learning research aimed at solving complex tasks through emergent computation [1, 2]. The interest in these techniques …
Erik Quaeghebeur
More info Gennaro Gala
Gennaro Gala
-

Evaluating Explanations of Model PredictionsMay 2024
The black-box nature of neural networks prohibits their application in impactful areas, such as health care or generally anything that would have consequences in the real world. In response to this, the field of Explainable AI (XAI) emerged. State-of-the-art methods in XAI define a …
ALAlexander LiuMore info
Sibylle Hess
-
Understanding Out-of-distribution DetectionMar 2024
There are numerous methods for out-of-distribution (OOD) detection and related problems in deep learning, see e.g. [1] for an overview. Many of these however only work well in highly fine-tuned settings and are not well understood in broader context. In this project, you would …
PTPim Tholhuijsen
Sibylle Hess
More info Jan Moraal
Jan Moraal
-

Diversity of recommendations in collaboration with Bol.comJan 2024
— completed —Recommender Systems (RSs) have emerged as a way to help users find relevant information as online item catalogs increased in size. There is an increasing interest in systems that produce recommendations that are not only relevant, but also diverse [1]. In addition to …
Mykola Pechenizkiy
More info
Hilde Weerts
-

Prompt Engineering for Large Language Models (taken)Dec 2023
GeneralAn internship at Accenture about prompt engineering for LLMs.RequirementsFrom our students we expect the following: high independence (including proposing own ideas);good understanding of mathematics (algebra, calculus, statistics, probability theory);good programming skills (Python + ML/DL libraries, preferably PyTorch). Thesis templatePlease take a look at this …
JBJoëlle BlinkMore info
Jakub Tomczak
-
k-Nearest Neighbor Imputation Under Monotonicity ConstraintsNov 2023
See PDF
IVIko Vloothuis
Wouter Duivesteijn
More info
Rianne Schouten
-
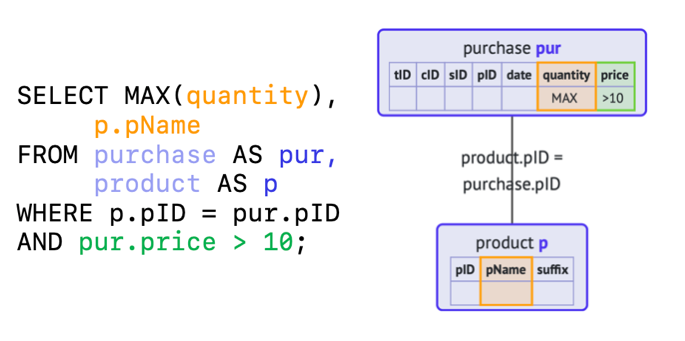
Execution and Visual Representations of SQL queries in case of syntax errorsSep 2023
Query formulation in SQL is difficult for novices, and many errors are made in query formulation. Existing research has focused on registering error types and frequencies. Not much attention has been paid to solving these problems. One of the problems in SQL is with …
BWBas Witters
George Fletcher
More info
Daphne Miedema
-

Efficient surrogates for the Ainslie wind turbine wake modelAug 2023
In wind farms, one source of reduction in power generation by the turbines is the reduction of wind speed in the wake downstream of each turbine's rotor. Namely, a turbine downstream in the wind direction of another will effectively experience wind with a reduced …
Erik Quaeghebeur
More infoLBLaurens Bliek (Information Systems, IE&IS) -

Object measurement by using computer vision (at a company)Aug 2023
Company: Datacation / aerovision.aiLocation: Eindhoven (AI Innovation Center at High Tech Campus) or Amsterdam (VU)Project descriptionAerovision.ai is a start-up that is building a no-code A.I. platform for drone companies. With this A.I. platform, companies can train, deploy and evaluate their customized computer vision algorithms, …
Jakub Tomczak
More infoACAt the company -
Correlation Detective on streaming dataJul 2023
Correlations are extensively used in all data-intensive disciplines, to identify relations between the data (e.g., relations between stocks, or between medical conditions and genetic factors). The 'industry-standard' correlations are pairwise correlations, i.e., correlations between two variables. Multivariate correlations are correlations between three or more variables. …
More info
Odysseas Papapetrou
-
(self-defined project on model-centric SD)Jul 2023
(irrelevant for self-defined project)
NSNiels SchellemanMore info
Wouter Duivesteijn
-
(self-proposed project on time-dependent SD)Jul 2023
(irrelevant)
BEBart EngelenMore info
Wouter Duivesteijn
-
Identifying robust instances in classificationJul 2023
In a classification task, some instances are classified more robustly than others. Namely, even with a large modification of the training set, these instances (in the test set) will be assigned to the same class. Other instances are non-robust in the sense that a …
More info
Erik Quaeghebeur