Master projects
Here you can find all our available master projects.
Open Projects (22)
-
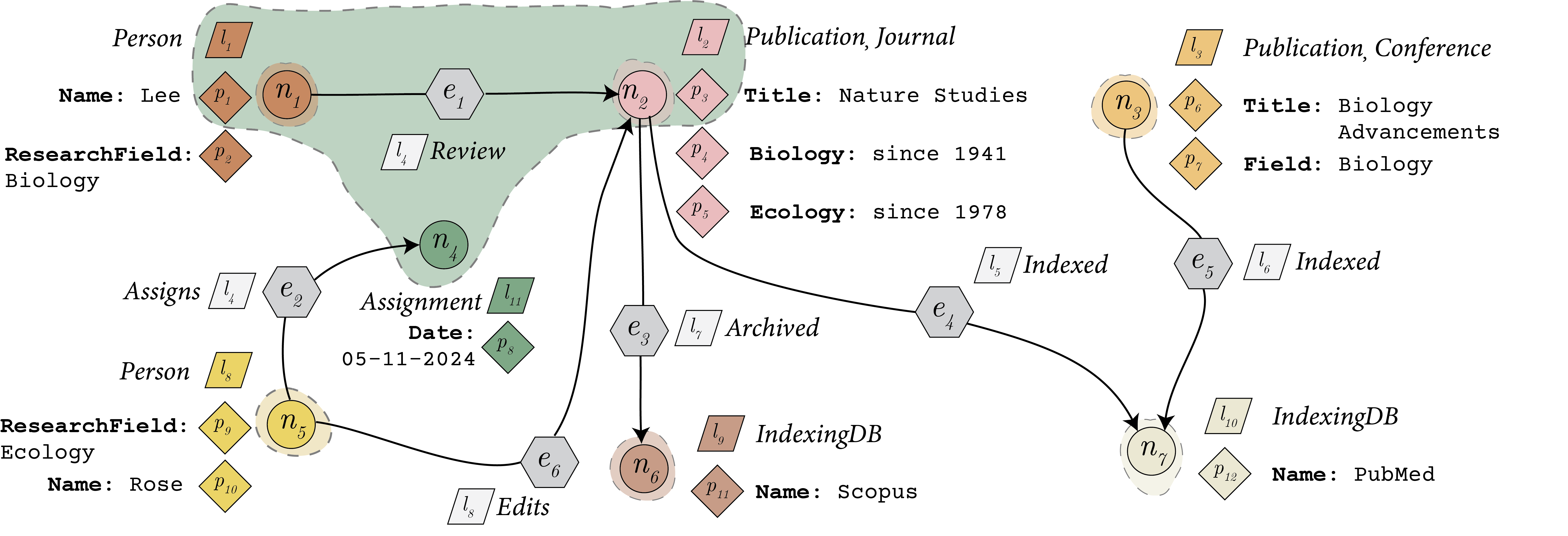
From Querying to Updating: Towards DML Support for a Metadata-Aware and Annotatable Graph Database
Property graph databases such as Neo4j are widely used these days for various applications like knowledge graphs backed LLM pipelines and modeling interconnected data, but traditional systems treat metadata (e.g., labels and property keys) separately from data and offer limited support for annotating subgraphs. …
 Nick Yakovets
More info
Nick Yakovets
More info Sepehr Sadoughi
Sepehr Sadoughi
-
Making the Invisible Visible: Identifying and Linking Internal Knowledge Sources in an Industrial KG
BackgroundMarel, a global leader in the food processing industry, specializes in designing and manufacturing advanced machinery for processing poultry, meat, and fish. Effective knowledge sharing among engineers at Marel is important for sustaining business operations. DescriptionThis project will explore how internally referenced knowledge sources—such as …
 George Fletcher
More info
Sepehr Sadoughi
George Fletcher
More info
Sepehr Sadoughi
-
Knowledge Archeology from Homebrew Data Sources: Integrating Informal Information Sources Into the KG
BackgroundMarel, a global leader in the food processing industry, specializes in designing and manufacturing advanced machinery for processing poultry, meat, and fish. Effective knowledge sharing among engineers at Marel is important for sustaining business operations. Description“Homebrew” systems are fragmented knowledge artifacts such as spreadsheets, ad-hoc …
George Fletcher
More info
Sepehr Sadoughi
-
Your own MSc project in databases at a company
If you have found a MSc project at a company with a strong database angle, then I am open to supervising. Note: a MSc project isn't an internship, and so the project must have a clear, relevant, and challenging research problem. Also, a strong …
More info Robert Brijder
Robert Brijder
-
Maintenance and Real-Time Updating of Deployed Knowledge Graphs
(This project is also available as an internship)Company: Marel Location: BoxmeerBackgroundKnowledge Graphs have emerged as a powerful tool for representing vast amounts of interconnected data. By structuring data in a graph format, enterprises can uncover relationships and insights that are often hidden in traditional …
Nick Yakovets
More info
Sepehr Sadoughi
-
Context-aware knowledge retrieval from KGs for technical support thinking assistant
Background: Knowledge Graphs (KGs) are structured representations of knowledge, that organize information in a graph-based format, where entities (nodes) and the relationships between them (edges) represent facts in an interconnected network. This graph-based structure enables encoding complex interrelationships and semantic information, making it an …
Nick Yakovets
More info
Sepehr Sadoughi
-
Implementing the Graph Pattern Matching Language (GPML) Fragment for GQL on AvantGraph
Graph databases have emerged as a powerful contender to traditional relational databases, especially in areas where complex relationships and interconnections are required, such as social networks and knowledge graphs. This has led to the development of various query languages to interact with graph databases, …
Nick Yakovets
More info
Sepehr Sadoughi
-
Show me the path: do people only care about paths?
Paths in graphs are natural, arising in domains as diverse as social networks (e.g., which people are in the same community?), communication networks (e.g., how does information spread via SMS messages?), and literary networks (e.g., which scientific papers are the most influential, in terms …
George Fletcher
More infoSBSourav Bhowmick (NTU Singapore) -
A Counterpart of SQL for Matrices
Most commercial databases are relational and use SQL to query the data. Often, however, data is not relational. Indeed, data scientists often deal with matrices instead of relations. A counterpart of SQL for the matrices is therefore needed, and initial progress has been reported …
More info
Robert Brijder
-
Programming Database Theory: Using a theorem prover to formalize database theory
Proving a theorem is similar to programming: in both cases the solution is a sequence of precise instructions to obtain the output/theorem given the input/assumptions. In fact, there are programming languages such as Lean, Coq, and Isabelle that can be used to prove theorems. …
More info
Robert Brijder
-
Personalized research project in graph data management
This is a wildcard for projects in (knowledge) graph data management.If you took EDS (Engineering Data Systems) and liked what we did there, we offer research+engineering projects in the scope of our database engine AvantGraph (AvantGraph.io). Topics include (but not limited to):- graph query …
Nick Yakovets
More info Bram van de Wall
Bram van de Wall
-
Schema language engineering in AvantGraph
Schema languages are critical for data system usability, both in terms of human understanding and in terms of system performance [0]. The property graph data model is part of the upcoming ISO standards around graph data management [4]. Developing a standard schema language for …
More info
George Fletcher
-
Cardinality estimation for factorized query processing
It is well-known that processing of complex analytical queries over large graph datasets introduces a major pain point - runtime memory consumption. To address this, recently, a method based on factorized query processing (FQP) has been proposed. It has been shown that this method …
More info
Nick Yakovets
-
Building benchmarks for modern graph databases
There exists a wide variety of benchmarks available for graph databases: both synthetic and real-world-based. However, one important problem with current state of the art in graph database benchmarking is that all of the existing benchmarks are inherently based on workloads from relational databases, …
More info
Nick Yakovets
-
Achieving main-memory query processing performance on secondary storage on graph query workloads
Since DRAM is still relatively expensive and contemporary graph database workloads operate with billion-node-scale graphs, contemporary graph database engines still have to rely on secondary storage for query processing. In this project, we explore how novel techniques such as variable-page sizes and pointer swizzling can …
Nick Yakovets
More info
Bram van de Wall
-

Explaining schema conformance for knowledge graphs: conformance reporting for WikiProjects members
Wikidata is an open collaboratively built knowledge base. In the Wikidata community groups of editors who share interest in specific topics form WikiProjects. As part of their regular work, members of WikiProjects would like to regularly test the conformance of entity data in Wikidata against schemas for entity classes. …
George Fletcher
More infoKUKatherine Thornton, Yale University (USA) -

Improving knowledge graph completeness with schemas: Wikidata and ShEx
In the collaboratively built knowledge base Wikidata some editors would appreciate suggestions of how to improve the completeness of items. Currently some community members use an existing tool, Recoin, described in this paper, to get suggestions of relevant properties to use to contribute additional statements. This process could …
George Fletcher
More infoKUKatherine Thornton, Yale University (USA) -
SIMD-based JSON data processing in a dynamic Language VM
The JSON data format is one of the most popular human-readable data formats, and is widely used in Web and Data-intensive applications. Unfortunately, reading (i.e., parsing) and processing JSON data is often a performance bottleneck due to the inherent textual nature of JSON. Recent …
More info Daniele Bonetta
Daniele Bonetta
-
ML-based compiler auto-tuning in GraalVM
Machine-learning based approaches [3] are increasingly used to solve a number of different compiler optimization problems. In this project, we want to explore ML-based techniques in the context of the Graal compiler [1] and its Truffle [2] language implementation framework, to improve the performance …
More info
Daniele Bonetta
-
Dynamic SQL query compilation in GraalVM
Data processing systems such as Apache Spark [1] rely on runtime code generation [2] to speedup query execution. In this context, code generation typically translates a SQL query to some executable Java code, which is capable of delivering high performance compared to query interpretation. …
More info
Daniele Bonetta
-
ML-based Profile-guided optimization in GraalVM
Profile-guided optimization (PGO) [1] is a compiler optimization technique that uses profiling data to improve program runtime performance. It relies on the intuition that runtime profiling data from previous executions can be used to drive optimization decisions. Unfortunately, collecting such profile data is expensive, …
More info
Daniele Bonetta
-
Sea-of-nodes graphs query and visualization
Language Virtual Machines such as V8 or GraalVM [3] use Graphs to represent code. One example Graph representation is the so-called Sea-of-nodes model [1]. Sea-of-nodes graphs of real-world programs have millions of edges, and are typically very hard to query, explore, and analyze. In …
More info
Daniele Bonetta
Assigned Projects (3)
-
High-Throughput Computational and Data Pipeline for iSCAT MicroscopyJun 2026
Interferometric scattering (iSCAT) microscopy is a technique to detect small particles (like individual proteins or live viruses) by capturing the interference between scattered light and a reference reflection. Currently, a major bottleneck is computational: there is a need for an end-to-end data streaming architecture …
Robert Brijder
More infoAKAnna Kashkanova -
Efficient database infrastructure for librariesNov 2025
Database management systems for libraries (as in, institutions for lending books) need to satisfy a number of specific needs, in particular regarding the types of queries that need to be supported and regarding performance of the queries that are most often executed. In this …
More info
Robert Brijder
-
Object-relational mapping for key-value databasesDec 2024
Object-relational mappers (ORM) like Django allow one to interact with a database in an object-oriented manner, and provide constructs for easy deployment of web-based applications that depend on a database. The underlying database of an ORM is typically a SQL database. It is unclear …
More info
Robert Brijder
Finished Projects (43)
-

A feasibility study on automated database exercise generation with large language modelsJul 2024
Your lecturers here at the university spend a lot of time creating new exercises for our students, both for weekly assignments as for exams. If you extrapolate this to universities and professional training globally, this is a tremendous effort and use of time. It …
WAWillem Aerts
George Fletcher
More info Daphne Miedema
Daphne Miedema
-

Analyzing progression of question difficulty for SQL questions on Stack OverflowJul 2024
SQL is difficult to use effectively, and creates many errors. Error types and frequency in SQL have been analyzed by various researchers, such as Ahadi, Prior, Behbood and Lister, and Taipalus and Siponen. One method of problem solving that computer scientists apply is posting …
BWBert Wijnhoven
George Fletcher
More info
Daphne Miedema
-
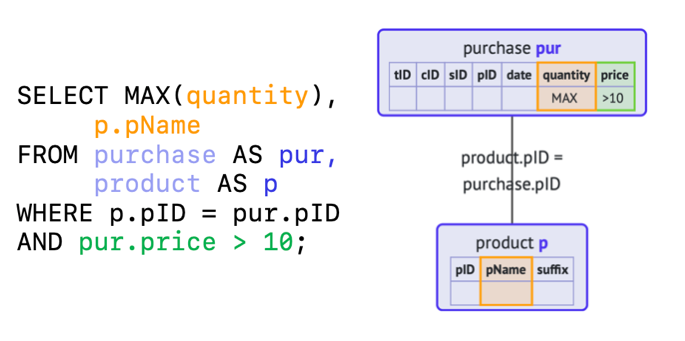
Execution and Visual Representations of SQL queries in case of syntax errorsSep 2023
Query formulation in SQL is difficult for novices, and many errors are made in query formulation. Existing research has focused on registering error types and frequencies. Not much attention has been paid to solving these problems. One of the problems in SQL is with …
BWBas Witters
George Fletcher
More info
Daphne Miedema