Project: Topics in Continual Lifelong Learning
Description
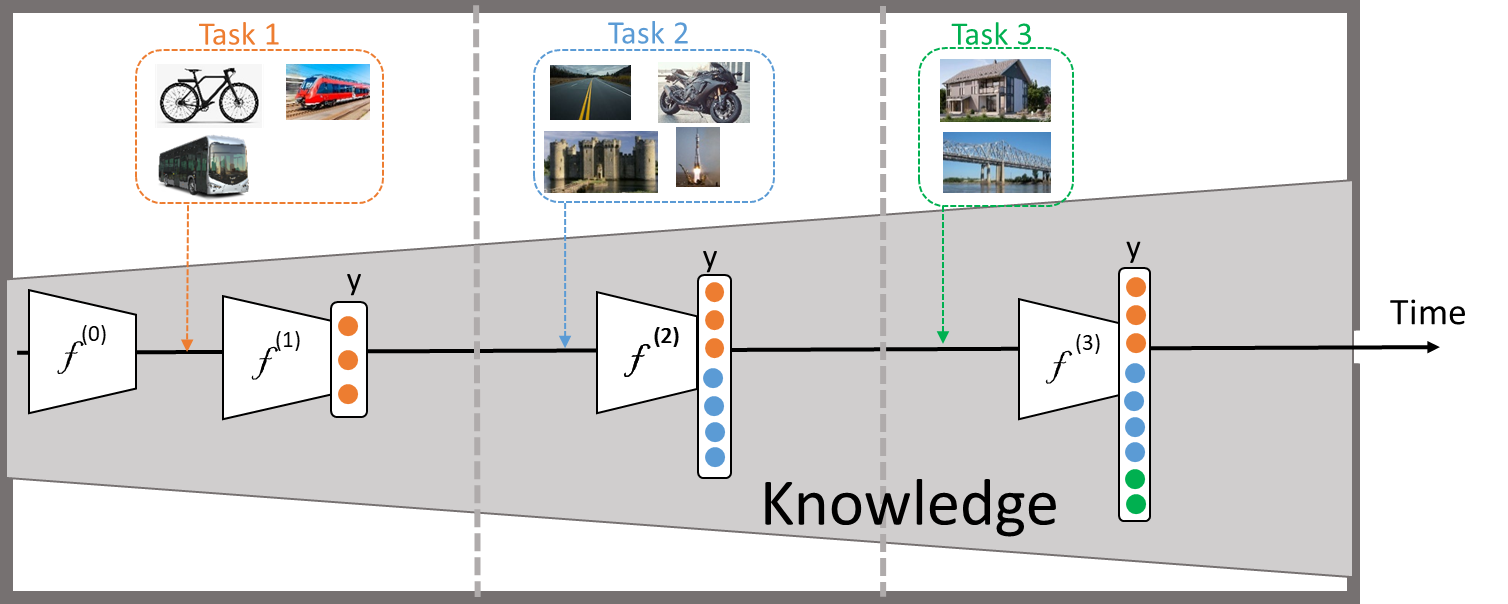
Nowadays, data changes very rapidly. Every day new trends appear on social media with millions of images. New topics rapidly emerge from the huge number of videos uploaded on Youtube. Attention to continual lifelong learning has recently increased to cope with this rapid data change. This paradigm aims to learn agents based on deep neural networks that can operate in open environments and become more and more knowledgeable over time. In particular, a neural network learns a sequence of tasks over time with non-stationary data distribution. The network uses the knowledge learned in the past to help in future learning.
The main challenge in this paradigm is that the network forgets the previously learned knowledge when the model is optimized for a new task. This phenomenon is known as catastrophic forgetting. Architectural strategy is a class of methods that alter the network structure to reduce interference between tasks. One of the recent directions is to learn a sparse subnetwork for each new task to avoid forgetting the previously learned ones [1,2,3,4].
In this project, we aim to address the ability to selectively transfer knowledge from the past that will help in learning/adapting to new tasks quickly using a few samples. At the same time, the network should maintain the previously learned knowledge and avoid catastrophic forgetting. One can explore the architectural strategy to selectively learn using some of the previously learned weights and update some others. The selective choice of connections during training could not only help in forward transfer but also improve the performance of previously related learned tasks using the new data.
[1] Mallya, Arun, and Svetlana Lazebnik. "Packnet: Adding multiple tasks to a single network by iterative pruning." Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018.
[2] Wortsman, M., Ramanujan, V., Liu, R., Kembhavi, A., Rastegari, M., Yosinski, J., & Farhadi, A. (2020). Supermasks in superposition. Advances in Neural Information Processing Systems, 33, 15173-15184.
[3] Ghada Sokar, Decebal Constantin Mocanu, and Mykola Pechenizkiy. "Spacenet: Make free space for continual learning." Neurocomputing 439 (2021): 1-11.
[4] Gurbuz, Mustafa B., and Constantine Dovrolis. "NISPA: Neuro-Inspired Stability-Plasticity Adaptation for Continual Learning in Sparse Networks." International Conference on Machine Learning. PMLR, 2022.
[5] Kang, Haeyong, Rusty John Lloyd Mina, Sultan Rizky Hikmawan Madjid, Jaehong Yoon, Mark Hasegawa-Johnson, Sung Ju Hwang, and Chang D. Yoo. "Forget-free Continual Learning with Winning Subnetworks." In International Conference on Machine Learning, pp. 10734-10750. PMLR, 2022.
Details
- Supervisor
-
 Mykola Pechenizkiy
Mykola Pechenizkiy
- Secondary supervisor
-
 Ghada Sokar
Ghada Sokar
- Interested?
- Get in contact