Project: Using Privilled Information in Sequential Decision Making with Partial Observations
Description
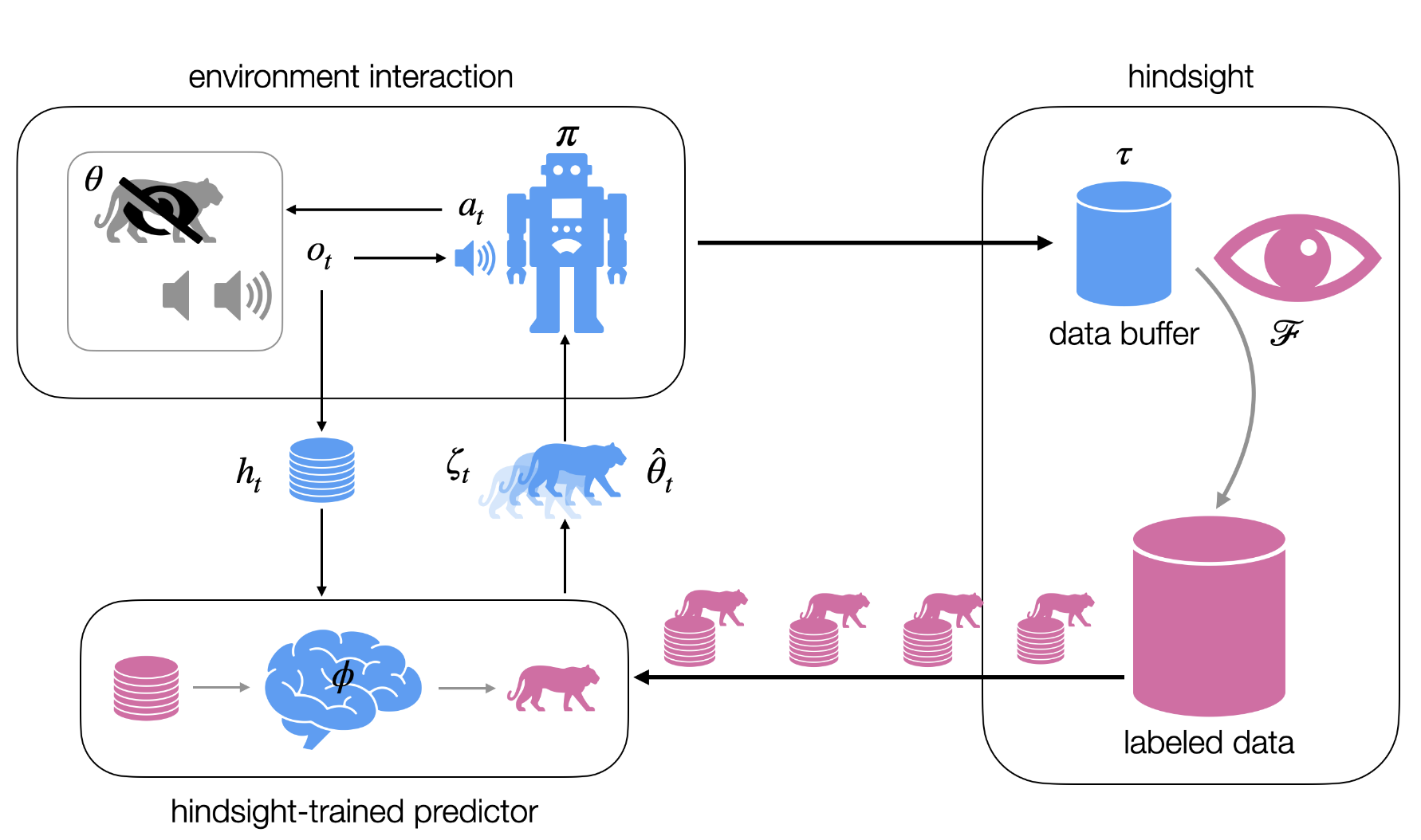
Reinforcement Learning (RL) (Sutton and Barto, 2018) addresses problems that can be modeled as a Markov decision process (MDP) (Puterman, 1994), where the transition function is unknown. In situations where an arbitrary policy is already in execution and the experiences with the environment were recorded in a dataset, an offline RL algorithm can use this dataset to compute a new policy, without having to collect more data (Levine et al., 2020).
The methods to tackle such problems typically assume that the available data provides complete and noise-free information about the environment. However, in most applications, the data is only partially observable, meaning it might be incomplete and noisy. However, computing a policy in such a setting is extremely challenging.
In this project, we consider a setting where a dataset of trajectories is available in a partially observable setting, making the key assumption that we can label the available trajectories with the hidden state. Based on this data, we can estimate the transition function and observation function, which facilitates the learning of a belief-based policy. Alternatively, we may assume an expert policy is available based on the underlying MDP, which can bias the optimization of the partially observable policy (Li et al., 2025).
A similar setting is explored in the supervised learning setting, known as learning using privileged information (LUPI) (Vapnik and Vashist, 2009). Therefore, the project aims to review the intersection of partial-observable offline RL and learning using privileged information.
References
- Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Offline reinforcement learning: Tutorial, review, and perspectives on open problems.
- Li, J., Zhao, E., Wei, T., Xing, J., and Xiang, S. (2025). Leveraging privileged information for partially observable reinforcement learning. IEEE Trans. Games, 1–11.
- Puterman, M. L. (1994). Markov decision processes: Discrete stochastic dynamic programming (1st ed.). John Wiley & Sons, Inc.
- Sutton, R. S., and Barto, A. G. (2018). Reinforcement learning: An introduction (2nd ed.). MIT press.
- Vapnik, V., and Vashist, A. (2009). A new learning paradigm: Learning using privileged information. Neural Networks, 22(5–6), 544–557.
Details
- Supervisor
-
 Thiago Simão
Thiago Simão
- Secondary supervisor
-
 Maryam Tavakol
Maryam Tavakol
- Interested?
- Get in contact