Project: Understanding deep learning – exploring the development of complexity in neural networks over depth and time
Description
Introduction:
When we train deep, nonlinear neural networks, we often assume that the applied transformations at every layer are effectively nonlinear. Earlier work (Kalimeris et al., 2019)has shown that in the beginning of training, the complete function that deep, nonlinear networks implement is close to linear. This might be due to the nature of activation functions: when you think about different activation functions, you can see that there is often a regime in which these functions are effectively linear. E.g., when the input to a ReLU function is a positive value, the ReLU function acts as a linear function. With a bit of handwaving, you could say the assumed ‘nonlinearity’ is thus not always there.
This means the models we train are much less powerful in the beginning of training than we assume them to be. During training, neural networks then gradually become more complex, i.e., the functions they implement become highly nonlinear. On the one hand, understanding this process would increase our general understanding of how neural networks work. On the other hand, a better understanding of the model capacity and the relationship with the dataset at all points during training could lead to better model designs and training procedures.
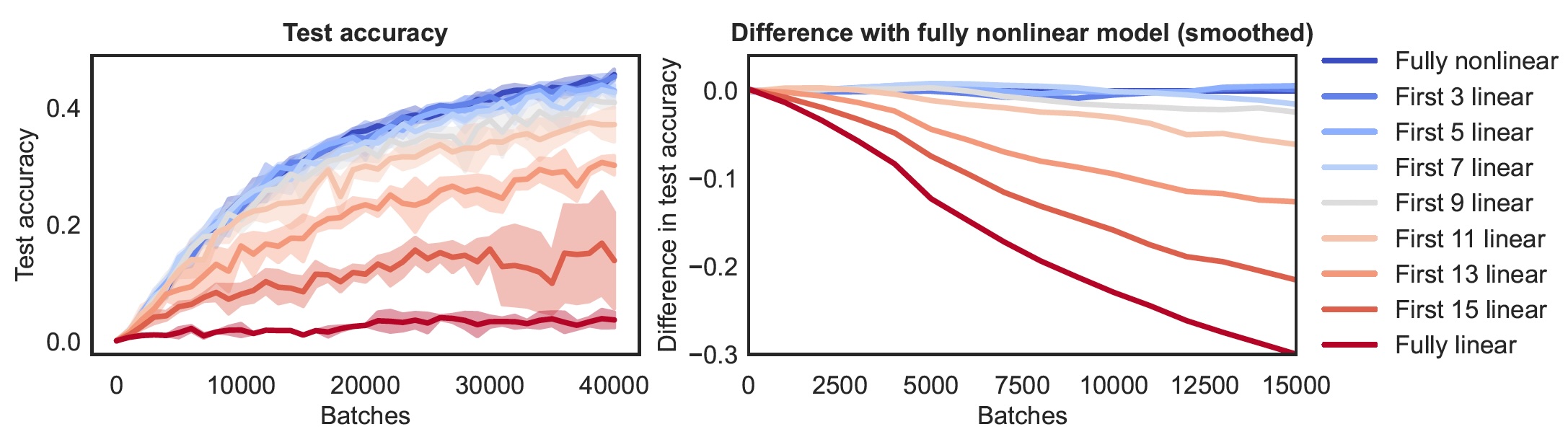
In our recent work (Pinson et al., 2024), we have experimentally explored this evolution over depth and time, i.e., over training updates and per layer. With some very simple experiments, we showed that the networks we trained started out with most of their layers in a linear-like regime, and the layers became effectively nonlinear in the direction from deeper to shallow layers during training.
This project:
(There are more related projects to come, so contact me if you're interested in general.)
In this project, you would extend this work (Pinson et al., 2024) to more architectures, datasets and training settings. Do transformers show the same behavior? Does it depend on the dataset used? Does the initialization or learning rate have an influence? We can discuss and brainstorm about the possible directions to take, after which you can refine your project during the preparatory phase.
This project is mostly experimental, and it requires excellent machine learning skills. In the preparatory phase, you will work with simple datasets and architectures such as simple CNNs and CIFAR-10. During the graduation phase, you will train more complicated models with GPUs and larger datasets. You thus need to be familiar and comfortable with training complex deep learning models on different datasets. Ambitious students can extend this project even further and could, with our help, try to gain insights in the mechanisms underlying the experimental results.
To read:
Kalimeris, D., Kaplun, G., Nakkiran, P., Edelman, B., Yang, T., Barak, B., & Zhang, H. (2019). SGD on Neural Networks Learns Functions of Increasing Complexity. Advances in Neural Information Processing Systems 32. https://proceedings.neurips.cc/paper/2019/hash/b432f34c5a997c8e7c806a895ecc5e25-Abstract.html
Pinson, H., Boland, A., Ginis, V., & Pechenizkiy, M. (2024). Exploring the development of complexity over depth and time in deep neural networks. ICML Workshop on High Dimensional Learning Dynamics. https://openreview.net/pdf?id=ZBU0mS0LdC
Details
- Supervisor
-
 Hannah Pinson
Hannah Pinson
- Secondary supervisor
-
 Aurélien Boland
Aurélien Boland