Project: Self-growing neural networks: using AutoML to Search for Incremental Learning Architectures
Description
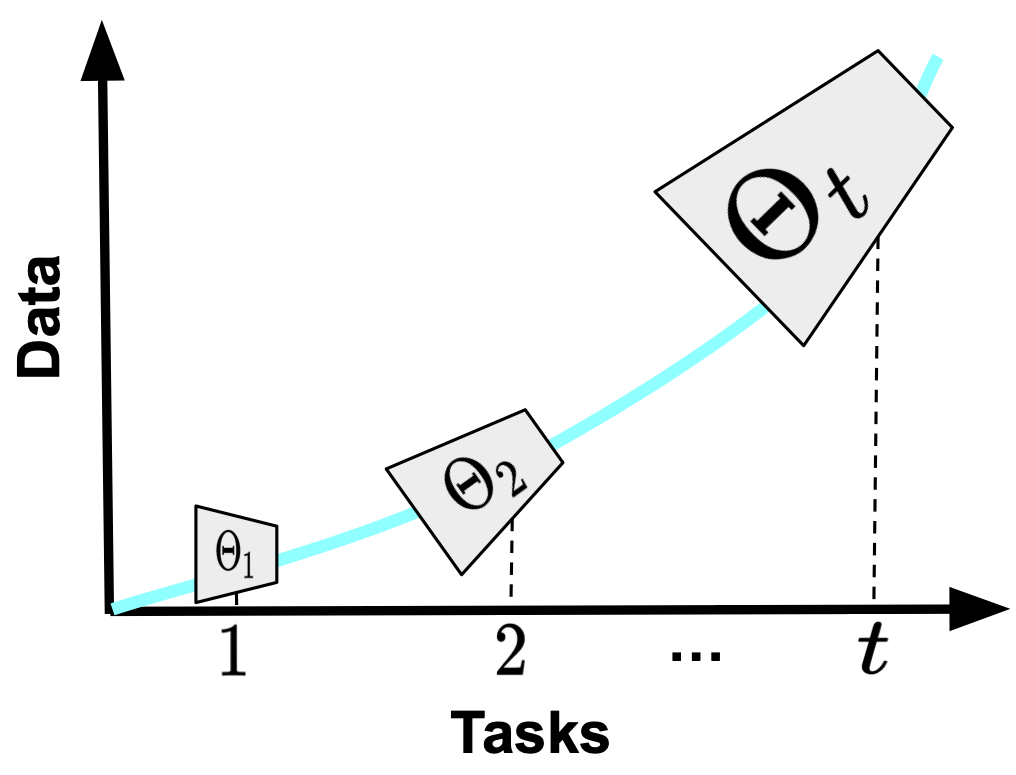
In incremental learning, when a new learning task arrives, a deep neural network is trained to map the input to the output space. As a result, at the end of the learning, we have 𝑡 different states of the learner, each starting from the previously trained model weights.
The limitation of the backbone is the fixed capacity of the learner through all learning sessions. Incremental learners are implemented with deep neural networks such as a ResNet-18, and the model weights are updated with the learning task data. However, the architecture remains the same, even though the learning tasks are getting more complex: More categories to distinguish across, and more data to fit. It is well known that bigger models perform better with larger-scale data (Ramasesh et al., 2022; Niu et al., 2021), and that architecture matters in continual learning problems (Mirzadeh et al., 2022). Ideally, we should be able to automatically adjust the size of the backbone to fit the needs of the learning task(s).
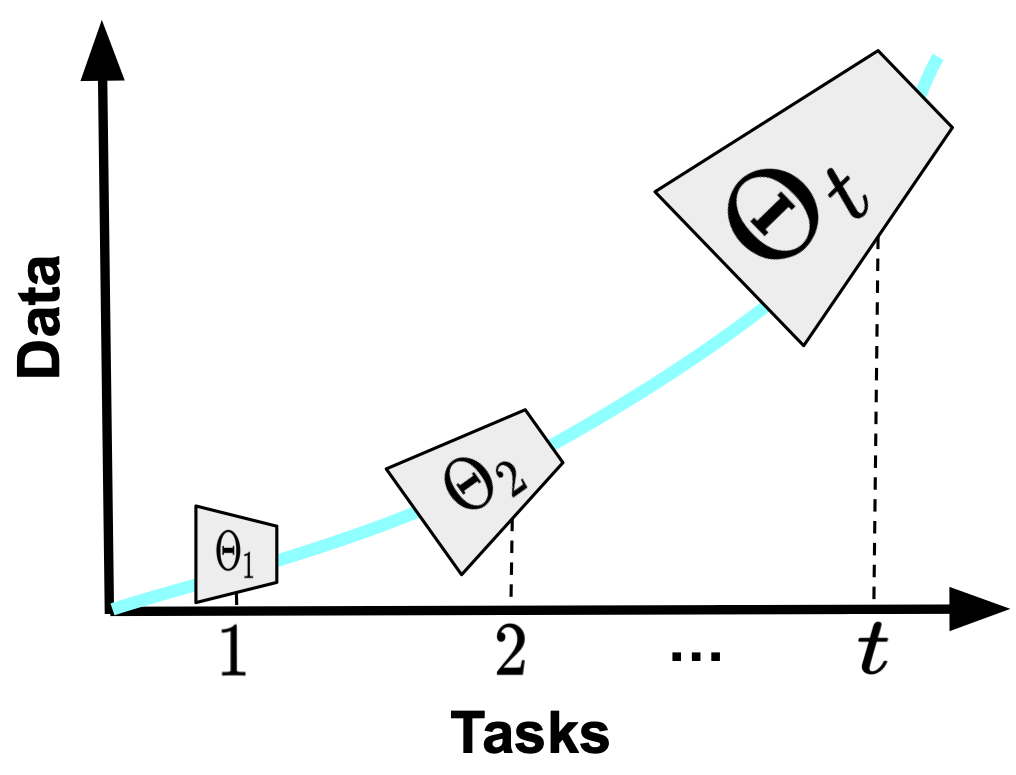
Consider the figure. Here, incremental learning starts with a relatively smaller network. As the size of the observed data and categories grows, so does the capacity of the incremental learner.
AutoML can optimize the learning backbone with respect to the learning tasks, with the help of Neural Architecture Search (NAS) (White et al., 2023). A particular challenge here is to be extremely efficient, (re)designing neural architectures that achieve maximum performance while minimizing computation (i.e., FLOPS). Specific NAS concepts such as compound scaling (Tan and Le, 2019) or meta-learning (Elsken et al., 2020; van Gastel and Vanschoren, 2022) can play a significant role here. Moreover, while traditional NAS methods optimize downstream task loss, e.g. cross-entropy loss for classification, incremental learning requires this to be coupled with across-task anti-forgetting objectives, and hence include incremental learning methods such as weight and data regularization or episodic memory.
Reading:
Ramasesh, V. V., Lewkowycz, A., and Dyer, E. (2022). Effect of scale on catastrophic forgetting in neural networks. In International Conference on Learning Representations.
Niu, S., Wu, J., Xu, G., Zhang, Y., Guo, Y., Zhao, P., Wang, P., and Tan, M. (2021). Adaxpert: Adapting neural architecture for growing data. In International Conference on Machine Learning, pages 8184–8194. PMLR.
Mirzadeh, S., Chaudhry, A., Yin, D., Nguyen, T., Pascanu, R., Görür, D., and Farajtabar, M. (2022). Architec- 177 ture matters in continual learning. CoRR, abs/2202.00275.
White, C., Safari, M., Sukthanker, R., Ru, B., Elsken, T., Zela, A., Dey, D., and Hutter, F. (2023). Neural 199 architecture search: Insights from 1000 papers. arXiv preprint arXiv:2301.08727.
Elsken, T., Staffler, B., Metzen, J. H., and Hutter, F. (2020). Meta-learning of neural architectures for few-shot 155 learning. CVPR.
van Gastel, R. and Vanschoren, J. (2022). Regularized meta-learning for neural architecture search. In AutoML 193 Workshop Track.
Tan, M. and Le, Q. V. (2019). Efficientnet: Rethinking model scaling for convolutional neural networks. 191
CoRR, abs/1905.11946.
Details
- Supervisor
-
 Joaquin Vanschoren
Joaquin Vanschoren
- Interested?
- Get in contact